Figure
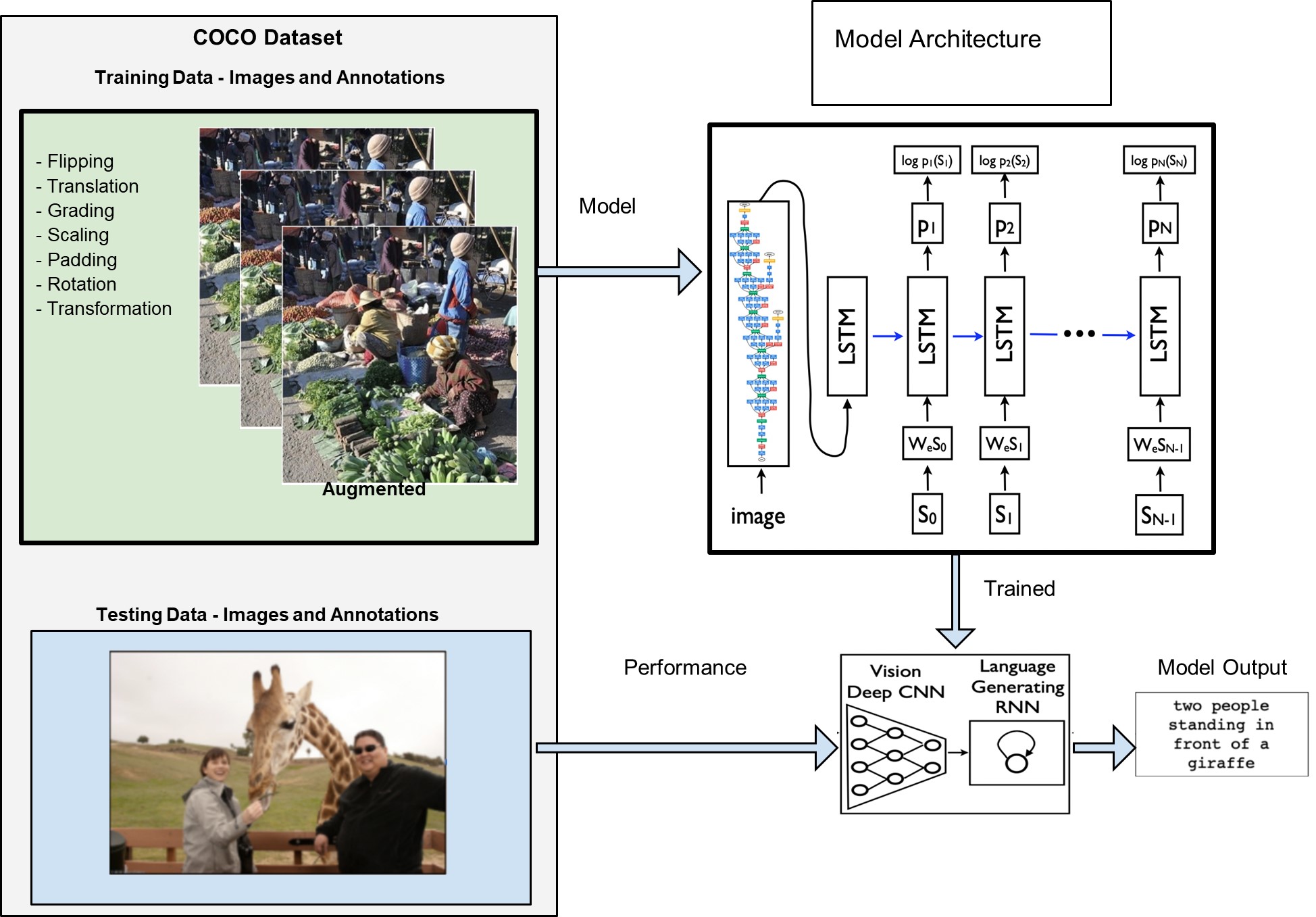
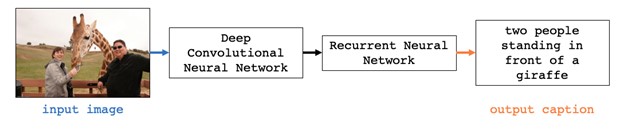
Conceptual Review
The original Neural Image Caption (NIC) model, as described in the 2015 paper by Oriol Vinyals, et. al., is composed of a deep convolutional neural network (CNN) and a recurrent neural network (RNN), which act as the encoder and decoder, respectively [5]. The CNN was first pre-trained for image classification tasks, then used to embed the input image into a fixed-length vector. The last hidden layer is thereafter provided as visual input directly to the RNN. The authors chose to use a Long-Short Term Memory (LSTM) net as the RNN for sequence modeling because of its ability to handle vanishing and exploding gradients. The loss function is the sum of the negative log likelihood of the correct word at every step: $${L(I, S) = - \sum_{t = 1}^{N}{\log {p_t(S_t)}}}$$ Where I is the image, S is the sentence, and t is the step. For inference and sentence generation, the BeamSearch approach was selected, which iteratively considers the set of k best sentences up to time t. BLEU, METEOR, and CIDER scores were reported for model evaluation, but perplexity is also mentioned as a metric used for tuning hyperparameters and model selection.
Specific Implementation Details
For our dataset, we used the MSCOCO dataset for annotations and images [2] and utilized the COCO API to facilitate loading, parsing, and visualization of the dataset [1]. We used 128 batch size, 300 embedding size, 3 epochs, 0.001 learning rate, and length of caption size divided by batch size for steps as hyperparameters. The NIC architecture utilizes resnet50 with a web embedding linear layer to encode the input. This encoding is passed through an embedding, LSTM, and linear layers to decode the encoding, which is lastly passed through cross entropy for loss. Training ran overnight and was able to successfully save the best model possible in 3 epochs. Please see the source code here
Our Findings
A major obstacle that we avoided was to not recode something that exists as an online resource. At first we attempted to
use Li Tong's PyTorch implementation [4] for NIC, but had issues downloading Visual Genome from Stanford. Eventually, we
found a model created by Shwetank Panwar [3] that allowed us to train a model with a publicly available dataset. However,
there were many difficulties loading the actual dataset into the original model due to compiling complications. This was
solved by simply modifying the source code to specify the file paths on our own machine and installing the pycocotools
package [1].
Before running the model, we expected that the process to load/download data and run an existing model. However, Li's model
needed the bottom up attention approach to extract annotations from images. Surprisingly, the method labels segments of each
image and records the areas of these segments. In contrast, Shwetank's approach used the MSCOCO dataset, which is a large
pre-existing dataset that already has human-generated annotations for each image.
Another issue we had was accessing the Discovery cluster to run the model. When ran on a regular MacBook Pro, the model took
a very long time to go through each epoch. By reducing the number of steps, we were able to run the code without any errors,
but the output captions had no meaning and did not correctly describe the images. Luckily, we have access to a Geforce RTX 3070
on one of our local machines and were able to complete all steps and epochs to successfully capture text from images.

Our Plans
Since our implementation was successful, we have decided to not change our plan, but to examine the code in more finer detail to see if we can augment the images and adjust the algorithm for the word embeddings. We also plan to tune our hyperparameters because we have encountered sub-optimal results even with a large and robust dataset such as MSCOCO. Furthermore, we would like to utilize other smaller datasets to apply these new techniques. In particular, the original NIC paper tested the model on the Flickr8k dataset, which contains only 6,000 training images compared to MSCOCO's 82,783 training size. We hypothesize that data augmentation and word vector embedding adjustment will be most effective with a significantly smaller dataset, having less training data adversely affects model performance.
Training Loss
Epoch [1/3], Step [100/4624], Loss: 4.0569, Perplexity: 57.7956
Epoch [1/3], Step [200/4624], Loss: 3.5360, Perplexity: 34.3293
Epoch [1/3], Step [300/4624], Loss: 3.3388, Perplexity: 28.1865
Epoch [1/3], Step [400/4624], Loss: 3.4730, Perplexity: 32.2341
Epoch [1/3], Step [500/4624], Loss: 3.3176, Perplexity: 27.5935
Epoch [1/3], Step [600/4624], Loss: 3.0715, Perplexity: 21.5750
Epoch [1/3], Step [700/4624], Loss: 3.0354, Perplexity: 20.8096
Epoch [1/3], Step [800/4624], Loss: 3.5567, Perplexity: 35.0487
Epoch [1/3], Step [900/4624], Loss: 3.0416, Perplexity: 20.9397
Epoch [1/3], Step [1000/4624], Loss: 3.1100, Perplexity: 22.4215
Epoch [1/3], Step [1100/4624], Loss: 3.1061, Perplexity: 22.3334
Epoch [1/3], Step [1200/4624], Loss: 2.9701, Perplexity: 19.4932
Epoch [1/3], Step [1300/4624], Loss: 3.0268, Perplexity: 20.6320
Epoch [1/3], Step [1400/4624], Loss: 3.1963, Perplexity: 24.4429
Epoch [1/3], Step [1500/4624], Loss: 2.9142, Perplexity: 18.43321
Epoch [1/3], Step [1600/4624], Loss: 2.8050, Perplexity: 16.5276
Epoch [1/3], Step [1700/4624], Loss: 2.8004, Perplexity: 16.4509
Epoch [1/3], Step [1800/4624], Loss: 2.6666, Perplexity: 14.3903
Epoch [1/3], Step [1900/4624], Loss: 2.8845, Perplexity: 17.89523
Epoch [1/3], Step [2000/4624], Loss: 2.6266, Perplexity: 13.82601
Epoch [1/3], Step [2100/4624], Loss: 2.8261, Perplexity: 16.8788
Epoch [1/3], Step [2200/4624], Loss: 2.5115, Perplexity: 12.3236
Epoch [1/3], Step [2300/4624], Loss: 2.5535, Perplexity: 12.8515
Epoch [1/3], Step [2400/4624], Loss: 2.6544, Perplexity: 14.2169
Epoch [1/3], Step [2500/4624], Loss: 2.5722, Perplexity: 13.0952
Epoch [1/3], Step [2600/4624], Loss: 2.6073, Perplexity: 13.5624
Epoch [1/3], Step [2700/4624], Loss: 2.5976, Perplexity: 13.4321
Epoch [1/3], Step [2800/4624], Loss: 2.5202, Perplexity: 12.4314
Epoch [1/3], Step [2900/4624], Loss: 2.5819, Perplexity: 13.2218
Epoch [1/3], Step [3000/4624], Loss: 2.9312, Perplexity: 18.7498
Epoch [1/3], Step [3100/4624], Loss: 2.5973, Perplexity: 13.4268
Epoch [1/3], Step [3200/4624], Loss: 2.6069, Perplexity: 13.5569
Epoch [1/3], Step [3300/4624], Loss: 2.4329, Perplexity: 11.3924
Epoch [1/3], Step [3400/4624], Loss: 2.6001, Perplexity: 13.4657
Epoch [1/3], Step [3500/4624], Loss: 2.8061, Perplexity: 16.54464
Epoch [1/3], Step [3600/4624], Loss: 2.4575, Perplexity: 11.6761
Epoch [1/3], Step [3700/4624], Loss: 3.3823, Perplexity: 29.4389
Epoch [1/3], Step [3800/4624], Loss: 2.4052, Perplexity: 11.0812
Epoch [1/3], Step [3900/4624], Loss: 2.8026, Perplexity: 16.4873
Epoch [1/3], Step [4000/4624], Loss: 2.6020, Perplexity: 13.4909
Epoch [1/3], Step [4100/4624], Loss: 2.5621, Perplexity: 12.9626
Epoch [1/3], Step [4200/4624], Loss: 2.2779, Perplexity: 9.75578
Epoch [1/3], Step [4300/4624], Loss: 2.4242, Perplexity: 11.2934
Epoch [1/3], Step [4400/4624], Loss: 2.5044, Perplexity: 12.2360
Epoch [1/3], Step [4500/4624], Loss: 2.3220, Perplexity: 10.1963
Epoch [1/3], Step [4600/4624], Loss: 2.3961, Perplexity: 10.9800
Epoch [2/3], Step [100/4624], Loss: 2.5168, Perplexity: 12.38846
Epoch [2/3], Step [200/4624], Loss: 2.4023, Perplexity: 11.0487
Epoch [2/3], Step [300/4624], Loss: 2.4429, Perplexity: 11.5068
Epoch [2/3], Step [400/4624], Loss: 2.2680, Perplexity: 9.66038
Epoch [2/3], Step [500/4624], Loss: 2.4190, Perplexity: 11.2352
Epoch [2/3], Step [600/4624], Loss: 2.3167, Perplexity: 10.1425
Epoch [2/3], Step [700/4624], Loss: 2.3787, Perplexity: 10.7911
Epoch [2/3], Step [800/4624], Loss: 2.3243, Perplexity: 10.2196
Epoch [2/3], Step [900/4624], Loss: 2.7533, Perplexity: 15.6950
Epoch [2/3], Step [1000/4624], Loss: 2.3826, Perplexity: 10.8329
Epoch [2/3], Step [1100/4624], Loss: 2.3576, Perplexity: 10.5656
Epoch [2/3], Step [1200/4624], Loss: 2.3375, Perplexity: 10.3551
Epoch [2/3], Step [1300/4624], Loss: 2.7576, Perplexity: 15.7612
Epoch [2/3], Step [1400/4624], Loss: 2.3340, Perplexity: 10.3192
Epoch [2/3], Step [1500/4624], Loss: 2.3380, Perplexity: 10.3606
Epoch [2/3], Step [1600/4624], Loss: 2.2557, Perplexity: 9.54214
Epoch [2/3], Step [1700/4624], Loss: 2.3957, Perplexity: 10.9763
Epoch [2/3], Step [1800/4624], Loss: 2.3566, Perplexity: 10.5548
Epoch [2/3], Step [1900/4624], Loss: 2.2948, Perplexity: 9.92223
Epoch [2/3], Step [2000/4624], Loss: 2.4178, Perplexity: 11.2208
Epoch [2/3], Step [2100/4624], Loss: 2.7617, Perplexity: 15.8271
Epoch [2/3], Step [2200/4624], Loss: 2.2335, Perplexity: 9.33271
Epoch [2/3], Step [2300/4624], Loss: 2.2385, Perplexity: 9.37893
Epoch [2/3], Step [2400/4624], Loss: 2.4666, Perplexity: 11.7827
Epoch [2/3], Step [2500/4624], Loss: 2.1577, Perplexity: 8.65149
Epoch [2/3], Step [2600/4624], Loss: 2.6249, Perplexity: 13.8030
Epoch [2/3], Step [2700/4624], Loss: 2.2723, Perplexity: 9.70219
Epoch [2/3], Step [2800/4624], Loss: 2.6656, Perplexity: 14.3771
Epoch [2/3], Step [2900/4624], Loss: 2.2771, Perplexity: 9.74820
Epoch [2/3], Step [3000/4624], Loss: 2.3031, Perplexity: 10.0055
Epoch [2/3], Step [3100/4624], Loss: 2.1792, Perplexity: 8.83897
Epoch [2/3], Step [3200/4624], Loss: 2.1188, Perplexity: 8.32090
Epoch [2/3], Step [3300/4624], Loss: 2.3300, Perplexity: 10.2781
Epoch [2/3], Step [3400/4624], Loss: 2.4946, Perplexity: 12.1173
Epoch [2/3], Step [3500/4624], Loss: 2.3013, Perplexity: 9.98699
Epoch [2/3], Step [3600/4624], Loss: 2.0987, Perplexity: 8.15596
Epoch [2/3], Step [3700/4624], Loss: 2.3092, Perplexity: 10.0668
Epoch [2/3], Step [3800/4624], Loss: 2.4013, Perplexity: 11.0379
Epoch [2/3], Step [3900/4624], Loss: 2.1849, Perplexity: 8.88970
Epoch [2/3], Step [4000/4624], Loss: 2.2873, Perplexity: 9.84817
Epoch [2/3], Step [4100/4624], Loss: 2.3020, Perplexity: 9.99376
Epoch [2/3], Step [4200/4624], Loss: 2.3504, Perplexity: 10.4901
Epoch [2/3], Step [4300/4624], Loss: 2.0934, Perplexity: 8.11238
Epoch [2/3], Step [4400/4624], Loss: 2.2477, Perplexity: 9.46580
Epoch [2/3], Step [4500/4624], Loss: 2.1116, Perplexity: 8.26133
Epoch [2/3], Step [4600/4624], Loss: 2.1205, Perplexity: 8.33518
Epoch [3/3], Step [100/4624], Loss: 2.2833, Perplexity: 9.808712
Epoch [3/3], Step [200/4624], Loss: 2.2020, Perplexity: 9.04357
Epoch [3/3], Step [300/4624], Loss: 2.2102, Perplexity: 9.11764
Epoch [3/3], Step [400/4624], Loss: 2.1971, Perplexity: 8.99935
Epoch [3/3], Step [500/4624], Loss: 2.1306, Perplexity: 8.42014
Epoch [3/3], Step [600/4624], Loss: 2.2045, Perplexity: 9.06600
Epoch [3/3], Step [700/4624], Loss: 2.1145, Perplexity: 8.28542
Epoch [3/3], Step [800/4624], Loss: 2.2796, Perplexity: 9.77292
Epoch [3/3], Step [900/4624], Loss: 2.4181, Perplexity: 11.2242
Epoch [3/3], Step [1000/4624], Loss: 1.9963, Perplexity: 7.3614
Epoch [3/3], Step [1100/4624], Loss: 2.2761, Perplexity: 9.73824
Epoch [3/3], Step [1200/4624], Loss: 3.6007, Perplexity: 36.6236
Epoch [3/3], Step [1300/4624], Loss: 2.2208, Perplexity: 9.21443
Epoch [3/3], Step [1400/4624], Loss: 2.1334, Perplexity: 8.44351
Epoch [3/3], Step [1500/4624], Loss: 2.2549, Perplexity: 9.53409
Epoch [3/3], Step [1600/4624], Loss: 2.0838, Perplexity: 8.03534
Epoch [3/3], Step [1700/4624], Loss: 2.1542, Perplexity: 8.62148
Epoch [3/3], Step [1800/4624], Loss: 2.0786, Perplexity: 7.99355
Epoch [3/3], Step [1900/4624], Loss: 2.0322, Perplexity: 7.63085
Epoch [3/3], Step [2000/4624], Loss: 2.3202, Perplexity: 10.1776
Epoch [3/3], Step [2100/4624], Loss: 2.0650, Perplexity: 7.88506
Epoch [3/3], Step [2200/4624], Loss: 2.7811, Perplexity: 16.1370
Epoch [3/3], Step [2300/4624], Loss: 2.1210, Perplexity: 8.33935
Epoch [3/3], Step [2400/4624], Loss: 2.0645, Perplexity: 7.88170
Epoch [3/3], Step [2500/4624], Loss: 2.3069, Perplexity: 10.0428
Epoch [3/3], Step [2600/4624], Loss: 2.1198, Perplexity: 8.32914
Epoch [3/3], Step [2700/4624], Loss: 2.2035, Perplexity: 9.05703
Epoch [3/3], Step [2800/4624], Loss: 2.1525, Perplexity: 8.60675
Epoch [3/3], Step [2900/4624], Loss: 2.1221, Perplexity: 8.34892
Epoch [3/3], Step [3000/4624], Loss: 2.0481, Perplexity: 7.75316
Epoch [3/3], Step [3100/4624], Loss: 2.2306, Perplexity: 9.30532
Epoch [3/3], Step [3200/4624], Loss: 2.1213, Perplexity: 8.34214
Epoch [3/3], Step [3300/4624], Loss: 2.9459, Perplexity: 19.0277
Epoch [3/3], Step [3400/4624], Loss: 2.2090, Perplexity: 9.10684
Epoch [3/3], Step [3500/4624], Loss: 2.1142, Perplexity: 8.28300
Epoch [3/3], Step [3600/4624], Loss: 2.1026, Perplexity: 8.18718
Epoch [3/3], Step [3700/4624], Loss: 2.1240, Perplexity: 8.36416
Epoch [3/3], Step [3800/4624], Loss: 2.0692, Perplexity: 7.91882
Epoch [3/3], Step [3900/4624], Loss: 3.0806, Perplexity: 21.7720
Epoch [3/3], Step [4000/4624], Loss: 2.1351, Perplexity: 8.45836
Epoch [3/3], Step [4100/4624], Loss: 2.1169, Perplexity: 8.30500
Epoch [3/3], Step [4200/4624], Loss: 2.1613, Perplexity: 8.68230
Epoch [3/3], Step [4300/4624], Loss: 2.8504, Perplexity: 17.2944
Epoch [3/3], Step [4400/4624], Loss: 2.6804, Perplexity: 14.5906
Epoch [3/3], Step [4500/4624], Loss: 1.9816, Perplexity: 7.25415
Epoch [3/3], Step [4600/4624], Loss: 2.1261, Perplexity: 8.38255
Epoch [3/3], Step [4624/4624], Loss: 2.1622, Perplexity: 8.69069
References
[1] Dollar, Piotr and Lin, Tsung-Yi. COCO API. Github repository, 2014
[2] Lin, Tsung-Yi, et al. Microsoft COCO: Common objects in context. European conference on computer vision. Springer, Cham, 2014
[3] Panwar, Shwetank NIC-2015-Pytorch. Github repository, 2019
[4] Tong, Li. NIC Model. Github repository, 2019
[5] Vinyals, Oriol, et al. Show and tell: A neural image caption generator. Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.