
The Song Search - DL
Team members
- Isha Hemant Arora (arora.isha@northeastern.edu)
- Praveen Kumar Sridhar (sridhar.p@northeastern.edu)
Introduction
Taking inspiration from Shazam, we hope to create a project that would be replicate the inner workings of Shazam and perform a retrieval task on musical data. The core of this IR system comes from finding efficient representations for songs and performing a retrieval task with the said representations. While trying to figure out our plan, we came across the fantastic resource Tensorflow Magenta and were intrigued by music transcription models so we decided to explore and experiment with a couple of these models.
Related Work
The papers that we are focusing on were written with the aim to achieve AMT (Automatic Music Transcription). AMT is valuable in not only helping with understanding but also enabling new forms of creation. The MT3 is the Multi-task Multitrack Music Transcription (Music Transcription with Transformers). As an overview we were able to see that while it is possible to separate different instruments and transcribe them separately, the architecture for different instruments would be different, thus making the process to implement different models per instrument long and tedious. More on this is explained in the next sections. The MT3 can process audio with multiple instruments and transcribe multiple different instruments to the MIDI standard.
We also tried understanding the model developed by Shazam and trying to relate it to the method we were trying to implement (the one where we process and transcribe audio data).
Onsets and Frames
The dual objectives are learned on each stack:
- Frame Prediction: Trained to detect every frame where a note is active.
- Onset Prediction: Trained to detect only onset frames (the first few frames of every note)
Each instrument needs a new architecture, but it is tedious to build a custom arch for each instrument.
Thus, the MT3 model was created.
MT3 (Multi-Task Multi-track Music Transcription)
It uses off-the-shelf transformers, as they work well if not better than custom neural networks as we had seen for Piano/Drums. They are modeled to take spectrograms as input and output a sequence of MIDI-like note events. It was modeled as a sequence-to-sequence task, using the Transformer architecture from T5. The major benefit of this model was if needed to retrain this architecture for newer instruments, we would only need to change the vocabulary of the output.

MIDI
MIDI is a communication standard that allows digital music gear to speak the same language. MIDI is short for Musical Instrument Digital Interface. It’s a protocol that allows computers, musical instruments, and other hardware to communicate.
Methods
To start off, we started with trying to understand and reproduce the models for Piano and Drum Transcription (Onsets and Frames) and then the models of Multi-instrument transcription (MT3). This is where we actually hit a snag, we weren’t very familiar with audio data and MIDI transcriptions and the original idea of trying to use string implementations over lyrical music and using it for matching audio clips had to be reformed.
We restructured our idea to work solely with instrumental data, all after trying to understand how the models parsed lyrical data (it was parsed as an instrument, generally the piano), with a pitch similar to the data.
Working with instrumental data, we decided that we could try and retrieve the vector representation of each song in our dataset and try using these representations to match with query vectors.
We decided to use the GTZAN dataset as available on Kaggle. The dataset consists of 10 genres of music, each genre having 100 instrumental audio clips, each being 30 seconds long. All files were originally in the .wav format, a format around which the model was created.
After transcription, we stored the data as such:
{
"audio_file_path": "sample1.wav",
"date_added": "11/23/2022",
"meta_data": {
"artist": "Bach",
"duration": "00:00:30",
"genre": "classical",
"transcribed_json_path": "transcribed_sample1.json"
}
}For each song, the format of transcribed JSON would be similar to (as created after transcription):
notes {
"pitch" : "40",
"velocity" : "127",
"start_time" : "3.33",
"end_time" : "3.45",
"instrument" : "2",
"program" : "42"
}
notes {
"pitch" : "29",
"velocity" : "127",
"start_time" : "3.45",
"end_time" : "3.56",
"instrument" : "2",
"program" : "42"
}
A 10-second audio file was introduced as the query. The file, also expected to be a .wav file was parsed and transcribed into a similar JSON format. A string matching algorithm was introduced with the idea of trying to find which data point in our dataset matches best with the query.
Architecture Diagram
For curating and transcribing the Dataset
.png)
For transcribing and matching the Query
.png)
We saved the dataset and query log for our project on our local MongoDB:

Experiments
To begin with, we first tried to understand the models for Onsets and Frames and MT3 and the MIDI transcription.
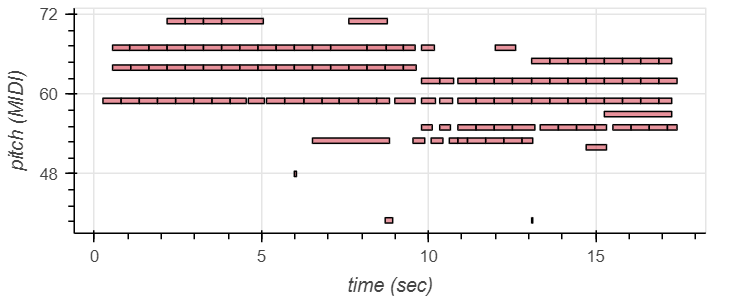
Piano Transcription
On transcribing a piano audio file (as added below), a pitch-against-time visualization was created.
The piano transcription model was created around two stacks.
Using the stacks for inference:
- The raw output of the onset detector is fed into the frame detector as an additional input
- The final output of the model is restricted to starting new notes only when the onset detector is confident that a note onset is in that frame.
Finally, the loss function used is the sum of two cross-entropy losses: one from the onset side and one from the frame side.
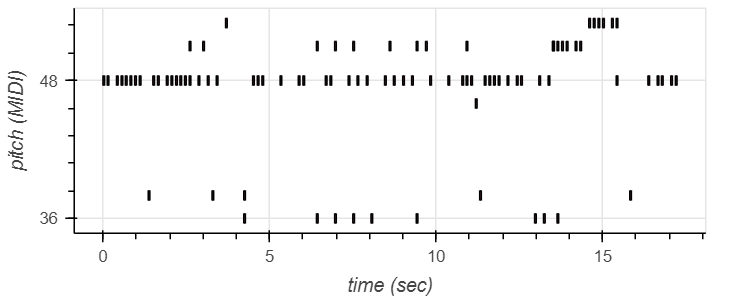
Drum Transcription
On transcribing a drum audio file (as added below), a pitch against time visualization was created.
We experimented with piano and drums transcription using the customized networks as suggested in the papers and observed the output (pitch vs time and transcription) on manually created audio files using the GarageBand software.
With this, we were able to see how these models are transcribing the audio it receives as input. The way these models transcribe audio is by converting them to MIDI format.
MIDI can be assumed to be a standardized language for music. On further exploration, we learned about instrument numbers which we realized was essential in understanding and interpreting the results of the models.
Multi-task Multitrack Music Transcription (MT3)
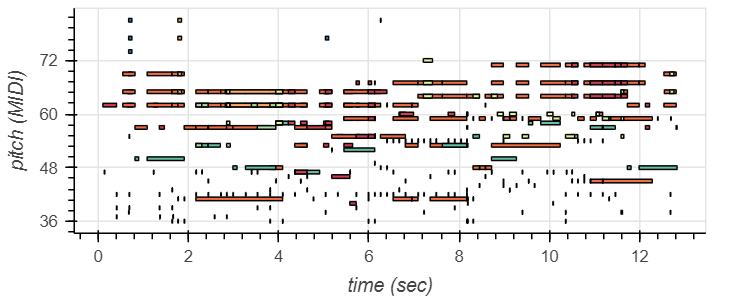
On creating a snippet of an audio file with multiple instruments (again on GarageBand), we were able to create a similar pitch against time visualization, this time for all the instruments in the audio file.
Wanting to experiment further, we wanted to see how the model would process audio with vocals (MIDI instrument numbers do not consider vocals).
To do this we passed a snippet of Ed Sheeran’s ‘I See Fire’. We were quite surprised to see how the vocals were encoded by the architecture.
To gain further clarity, we tried passing a pure audio clip of us speaking (no background instruments included). We noticed that the transcription and the MIDI audio were classed as that of a piano.
While a pretty good model, as outlined by the authors, we were also able to see the limitations of the architecture (and probably a suggestion for future work). The network does not consider velocity (as was considered in the focused Drum Transcription model) as all datasets (MT3 considers six) record velocity differently. It was also noted that the MusicNet dataset had some alignment errors and no attempts were made to correct them.
Genre Classification
The original idea was to pull vectors for each audio transcribed in the dataset and then match it to the query vectors and thus we tried implementing it. Since we were struggling with the same (the model was a little too complex for us), we then decided on trying to create a genre classifier, which we believed would give us vectors too, ones that we could try to match with the query vectors that would be created using this genre classifier.
Yet, when we created the genre classifier, we realized that the data that we were working with (1000 audio clips, 30 seconds each) was extremely small for us to be able to train a proper model (we tried multiple models; all the way from simple ANNs to LSTMs). Thus, the genre classifier itself was not well-trained and the vectors, irrespective of the genre, were very similar. Thus, query vectors when created, almost all had a cosine similarity of over 0.85 and best matches at the first position were not always true.
Vector Creation
Since our idea of using a genre classifier was not exactly successful, we tried yet another approach. Since we had converted our audio files into Mel Spectrograms, we got the matrix representations of that and then flatten them - that gave us vectors that we were able to use for matching with query vectors (which were also created using the Mel Spectrogram representations).
Piano Matching (Single instrument) v/s GTZAN clips (Multi-instrument)
As a part of the string matching with JSON, we considered two cases:
- Single Instrument (Piano files)
The first thing we saw was that the JSON created did not include the instrument (even though MIDI does have multiple types of instruments for a single style, so we were expecting to see its existence in the JSON). When we first created the matching algorithm, we created it using these clips as a reference and we were able to get an accuracy that was above 90% for the first song retrieved being the best match. This matching algorithm was created keeping the idea of Rabin-Karp in mind.
- Multiple Instruments (GTZAN dataset)
This dataset, when we first transcribed it into the JSON format, did have the instrument data. Testing the matching algorithm on this dataset, we noticed that there were a lot of issues and that the matching algorithm was not performing as well as we had hoped. To improve on it, we made a few more changes to the matching.
Results
When testing the MT3 model, we observed that:
- MT3 has an average frame F1 score of 0.85 across different datasets
- MT3 has an average onset F1 score of 0.8 across different datasets
When implementing the string-based matching algorithm on the JSON files created using:
- Single Instrument
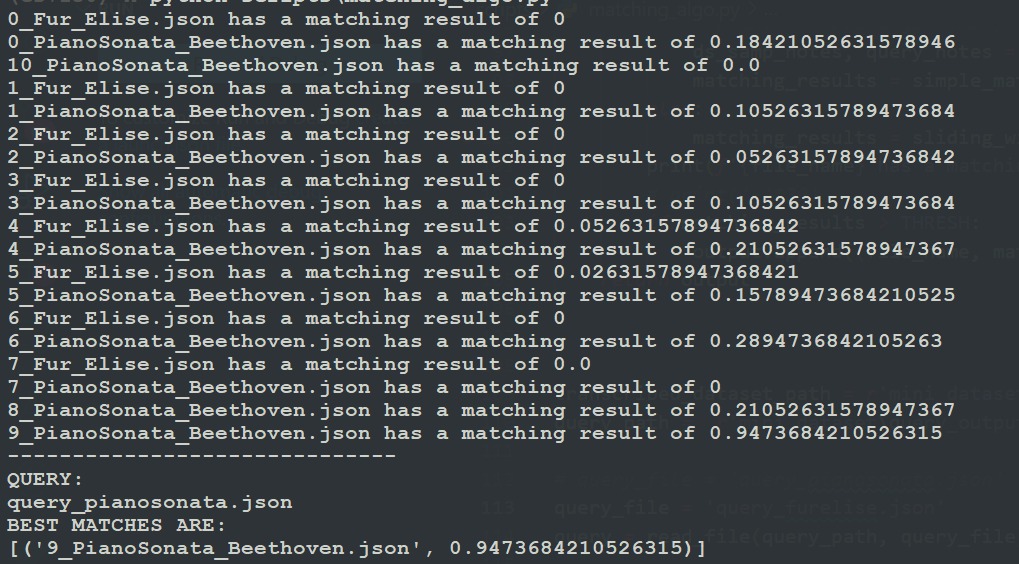
.jpeg)
- Multiple Instruments
The IR system with the MT3 model has an overall accuracy of 74% in the top 5 candidate set and a MAP of 0.68
.png)
Using the vector representations from the Mel Spectrograms had an overall accuracy of 51% in the top 5 candidate set.

Evaluation
We used the metrics for accuracy and MAP to test the Information Retrieval system that we had created.
Accuracy: It is an extremely intuitive performance measure. Simply, it is a ratio of correctly predicted observations to the total observations.
MAP (Mean Average Precision): The general definition for the Average Precision (AP) is finding the area under the precision-recall curve. MAP is the average of the Average Precision (AP).
Contributions and Future Work
We realize that the project did not include songs that contained lyrics as we were unable to parse and transcribe them in a way that was particularly useful. As a future extension, we hope to be able to extend this project of matching songs to include songs with lyrics.
References
- Main Paper/Blog
- Links:
- Hawthorne, Curtis, et al. "Sequence-to-sequence piano transcription with Transformers." arXiv preprint arXiv:2107.09142 (2021).
- Gardner, Josh, et al. "Mt3: Multi-task multitrack music transcription." arXiv preprint arXiv:2111.03017 (2021).
- https://magenta.tensorflow.org/transcription-with-transformers (the original blog)
- Links:
- Auxiliary Papers/Blogs
- https://towardsdatascience.com/3-reasons-why-music-is-ideal-for-learning-and-teaching-data-science-59d892913608 (Max Hilsdorf)
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
- Gong, Yuan, Yu-An Chung, and James Glass. "Ast: Audio spectrogram transformer." arXiv preprint arXiv:2104.01778 (2021).