The Song Search
Deep Learning - CS 7150
Prof. David Bau
September 29, 2022
Team members
- Praveen Kumar Sridhar (sridhar.p@northeastern.edu)
- Isha Hemant Arora (arora.isha@northeastern.edu)
In this second review, we first focused on understanding how music can be parsed and transcribed as in the blogs on Google Magenta (focusing on piano, drum, and multi-instrument transcription). We also focused on reading through and understanding the auxiliary papers and blogs that we had outlined in our proposal. One of the major topics we focused on was understanding MIDI thoroughly (the audio was being transcribed in the format and we were extremely intrigued about it).
Conceptual Review
The papers that we are focusing on were written with the aim to achieve AMT (Automatic Music Transcription). AMT is valuable in not only helping with understanding but also enabling new forms of creation. The MT3 is the Multi-task Multitrack Music Transcription (Music Transcription with Transformers). As an overview we were able to see that while it is possible to separate different instruments and transcribe them separately, the architecture for different instruments would be different, thus making the process to implement different models per instrument long and tedious. More on this is explained in the next sections. The MT3 can process audio with multiple instruments and transcribe multiple different instruments to the MIDI standard.
Implementation
The implementation that we have focused on until now is the reproduction of the inference pipelines for all the models introduced on Google Magenta by the team, that focus on the transcription. This includes:
- Piano Transcription
- Drums Transcription
- Multi-task Multitrack Music Transcription - MT3 (Multiple Instruments)
The models were created to transcribe .wav files.
Piano Transcription
As outlined in the Onsets and Frames: Dual-Objective Piano Transcription paper, shown below is the architecture in use. This system does an excellent job of capturing harmony, melody, and even rhythms. Originally trained on the MAPS (MIDI Aligned Piano Sounds) dataset, the model was retrained on the MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset.
The reason why the system works so well is because of the dual objectives set on the architecture to learn. The dual objectives are learned on each stack:
- Frame Prediction: Trained to detect every frame where a note is active.
- Onset Prediction: Trained to detect only onset frames (the first few frames of every note)

Drum Transcription
Taking inspiration and extending from the piano transcription, the model for drum transcription was designed. A major difference noticed when working with the dataset that was found was the need to consider velocity as a parameter to capture groove (the dataset was trained using a fixed velocity and the results were less than satisfactory). It was noticed that fixed velocity models would lose quite a bit of performance and evocative aspects of music. The model was trained on the E-GMD (Expanded Groove MIDI Dataset) dataset.
Similar to the piano transcription, the drum transcription too has dual objectives set on the architecture to learn. Since drum hits do not sustain like piano notes, frame predictions are unnecessary and not required.
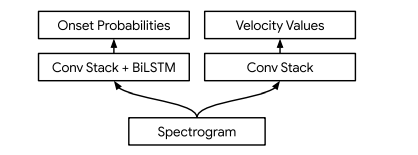
Multi-task Multitrack Music Transcription (MT3)
It uses off-the-shelf transformers, as they work well if not better than custom neural networks as we had seen for Piano/Drums. They are modeled to take spectrograms as input and output a sequence of MIDI-like note events.
Why Transformers?
The reasoning as provided by the authors is that transformer architecture has shown remarkable performance on a diverse set of tasks within both language and vision, which we agree with.
To test the validity of this statement, the authors first modeled piano transcription using a transformer instead of using the specialized architecture, as explained above. They modeled it as a sequence-to-sequence task, using the Transformer architecture from T5. They observed better results and higher F1 scores. Further, to retrain this architecture for newer instruments, we would only need to change the vocabulary of the output.
For multiple instruments, it is like needing to add new words to the output vocabulary. Thus, using the architecture as is.
Six datasets were used for the model, namely; MAESTROv3 (MIDI and Audio Edited for Synchronous TRacks and Organization), Slakh2100 (Synthesized Lakh), Cerberus4, GuitarSet, MusicNet, and URMP (University of Rochester Multi-Modal Music Performance).
A generic form of the MT3 model can be seen below:

Findings
Piano Transcription
On transcribing a piano audio file (as added below), a pitch-against-time visualization was created.

As mentioned in the Implementation, the piano transcription model was created around two stacks.
Using the stacks for inference:
- The raw output of the onset detector is fed into the frame detector as an additional input
- The final output of the model is restricted to starting new notes only when the onset detector is confident that a note onset is in that frame.
Finally, the loss function used is the sum of two cross-entropy losses: one from the onset side and one from the frame side.
Drum Transcription
On transcribing a drum audio file (as added below), a pitch against time visualization was created.
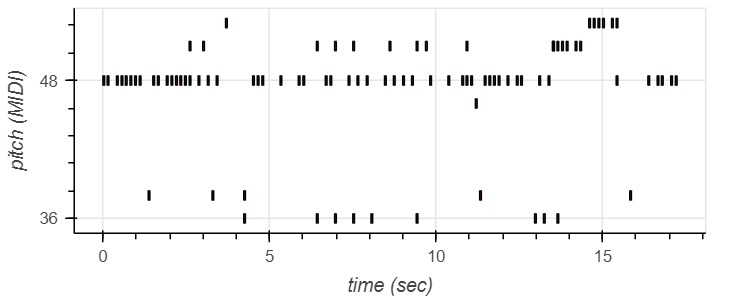
We experimented with piano and drums transcription using the customized networks as suggested in the papers and observed the output (pitch vs time and transcription) on manually created audio files using the GarageBand software.
With this, we were able to see how these models are transcribing the audio it receives as input. The way these models transcribe audio is by converting them to MIDI format.
MIDI can be assumed to be a standardized language for music. On further exploration, we learned about instrument numbers which we realized was essential in understanding and interpreting the results of the models.
Multi-task Multitrack Music Transcription (MT3)
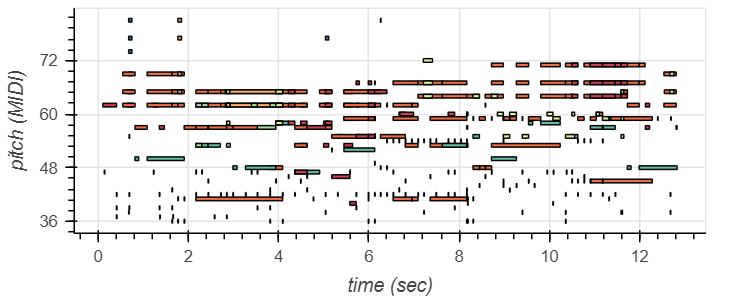
On creating a snippet of an audio file with multiple instruments (again on GarageBand), we were able to create a similar pitch against time visualization, this time for all the instruments in the audio file.
The following is an image of the transcribed data in text format.

Wanting to experiment further, we wanted to see how the model would process audio with vocals (MIDI instrument numbers do not consider vocals).
To do this we passed a snippet of Ed Sheeran’s ‘I See Fire’. We were quite surprised to see how the vocals were encoded by the architecture.
To gain further clarity, we tried passing a pure audio clip of us speaking (no background instruments included). We noticed that the transcription and the MIDI audio were classed as that of a piano.
While a pretty good model, as outlined by the authors, we were also able to see the limitations of the architecture (and probably a suggestion for future work). The network does not consider velocity (as was considered in the focused Drum Transcription model) as all datasets (MT3 considers six) record velocity differently. It was also noted that the MusicNt dataset had some alignment errors and no attempts were made to correct them.
Plans
Our original plan was to be able to create vector and string representations of the music as a major chunk of our project and then perform information retrieval tasks using these representations. For this, we were hoping to be able to work with complete songs, that included, both instruments and vocals. Now that we have analyzed the architecture we were hoping to use a little more closely and familiarized ourselves with the intricacies of the audio transcription and the MIDI format, we realize that being able to parse songs with vocals will be difficult. As such, we intend to redirect our project idea to simply consider instrumental files and create vector representations for those.
We also hope to speak to Professor Bau in regards to being able to find the best way to create these vector representations.
Links:
- Hawthorne, Curtis, et al. "Sequence-to-sequence piano transcription with Transformers." arXiv preprint arXiv:2107.09142 (2021).
- Callender, Lee, Curtis Hawthorne, and Jesse Engel. "Improving perceptual quality of drum transcription with the expanded groove midi dataset." arXiv preprint arXiv:2004.00188 (2020).
- Gardner, Josh, et al. "Mt3: Multi-task multitrack music transcription." arXiv preprint arXiv:2111.03017 (2021).