Automated essay scoring for English Language Learners
Introduction
English Language learners are students who are learning English as a second language. In many ways existing automated graders can be quite biased towards the language proficiency and may overlook the actual conceptual scaffolding of the essay. Integration of language competency into Deep Learning models can be uselful to accomodate for differences in English Language Learners.Formulaic grading is unfair especially for the individuals of various origins who have different cultural and linguistic traditions. When the sole language required to accomplish a task is English, it can be difficult to assess genuine learning.
This will help educators be more confident in relying on automatic graders knowing that they will evaluate a student's work fairly, considering knowledge and competent arguments regardless of language proficiency.Yang et al [1] have worked extensively on general great performance on automatic essay grading, Indeed by the literature review in this paper, transformer based representations seem to perform better than traditional recurrent layers. The main model that is proposed in this paper is called R2BERT, which is essentially the output of a BERT encoding fed into a mapping function, which is a composite function using both regression and ranking. Our idea of a deep learning model will take inspiration from the work of Yang et al. (2020), where an enhanced scoring model was used by combining a fine-tuned pre-trained BERT model with regression [2].
Background
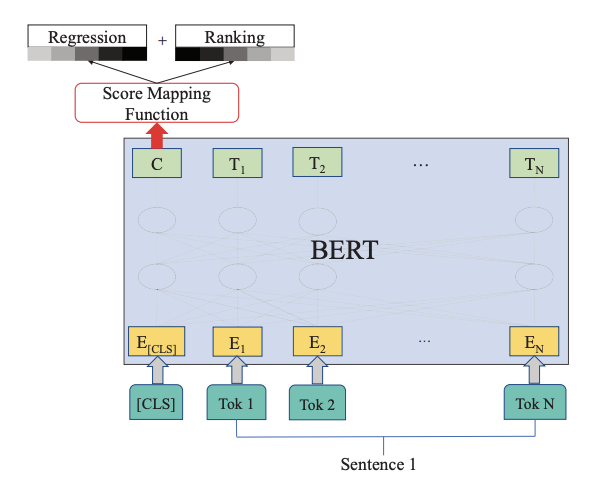
R2BERT is BERT model with regression and ranking, BERT is used to learn text representations to capture deep semantics. Then a fully connected neural network is used to map the representations to scores. Finally, regression loss and batch-wise ranking loss constrain the scores together, which are jointly optimized with dynamic combination weights. R2BERT takes a batch of essays as input. With preprocessing (adding a special token, [CLS], at the beginning of each essay), each token is transformed into its embedding and sent into the BERT model. The representations of all essays are the output vectors mapping to [CLS]. Essay scores could be obtained by passing the representations into the Score Mapping Function. They are constrained by regression loss and ranking loss, which are optimized jointly with the dynamic combination. As shown in the color bar, the weight of regression loss is gradually increasing, while that of ranking loss is decreasing.
BERT Encodings from generated logits are passed into a score mapping function, which performs regression as a fully connected layer. The results are then mapped using a ranking model based on list positioning and labels. From a pre-trained BERT model, we can obtain the hidden representations of all the input words. The hidden representation mapping to [CLS] (special token), r = h[CLS], is used as the text representation. With obtained text representation r, a fully connected neural network (FCNN) is used as the score mapping function. The regression loss is calcuted using the formula below.
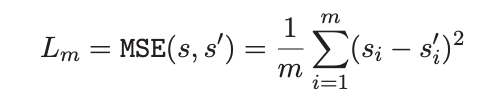
Ranking all of the essays at once is not practicable since each essay is large. We forego accuracy and only rate the essays in each batch, a method we refer to as batch-wise. ListNet. The batchwise loss function is calculated using the formula below.
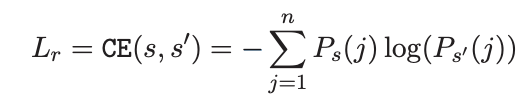
Now, we combine regression loss and batchwise loss, where τe is a σ function about e. E is the total number of the epochs, and e is the value of current epoch, γ is a hyper-parameter which is chosen such that τ1 = 0.000001.
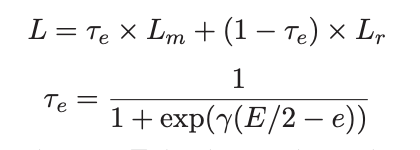
Method
Dataset
The dataset used here comprises argumentative essays written by 8th-12th grade English Language Learners (ELLs). The essays have been scored according to six analytic measures: cohesion, syntax, vocabulary, phraseology, grammar, and conventions. This datset is a part of Feedback Prize - English Language Learning challenge on kaggle.
Preprocessing
We will use use BERT base model (uncased) which is a transformers model pretrained on a sizable corpus of English data. We used BERT tokenizer to tokenize the essays, BERT add some special tokens [CLS] and [SEP] in addition to the input tokens. The [CLS] token must be used at the beginning and the [SEP] token must be used at the end of the sentence according to the BERT model's design.
The model always required input data in rectangular format, if we are passing data in a batch. We need to make the same length for all the samples in a batch. In that process, some padding value has to be added to the right side of the tokens in shorter sentences and to ensure the model will not look into those padded values attention mask is used with value as zero. Let’s have a real data problem for the same question answering data.
BERT has a limitation for number of tokens it can take as input which is 512. Tokens above the 512 range of the BERT input should are removed, so the tokenized representations of the essays were converted to split tokens with 512 as constant length. The sentence encodings smaller than this were padded with zeros, while longer sentences were truncated to fit the max length. Tokens Lemmatized is done to convert words to their base forms. Randomized static masking for Attention scores.
Base Model
Our base model is modified version of R2BERT. The output of BERT gave us learned encodings that were then fed into a fully connected model to get the actual predictions. We experimented with different learning rates and 1e-4 and 1e-5 seemed to perform the best. A smaller batch size was significantly better for the validation accuracy here since the total number of samples were relatively low when the depth of the model is considered. For the optimizer we picked Adam. We used modified ranking to include similarity scores. Hyperparameters of the model:
- Learning rate: 4e-5
- Epochs: ~10 (original paper has 30 but the dataset is a lot larger)
- Batch size: 16
- Max length of tokens: 512
Aditionally, we normalized the scores between 0 and 1, used Adam optimizer. The loss function we used was Mean Column-wise Root Mean Squared Error (Original paper had Quadratic Weighted Kappa)
Modified Model
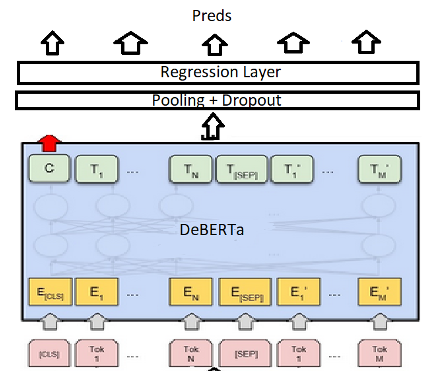
We used DeBERTa (Decoding-enhanced BERT with disentangled attention) for automated easy scoring. DeBERTa is designed as an improvement to BERT and RoBERTa Inherently utilizes position when computing masked language modeling to determine masked tokens. (Essentially considers the absolute positioning of a word in a sequence.) BERT represents a word as the combination of its word embedding as well as positioning embedding added together. DeBERTa keeps these two separate when calculating the attentions to better incorporate relative positions of tokens, attention heads are important when we think about ELLs. Hyperparameters of the model:
- Learning rate with linear decay – 5e-5 to 0
- Epochs: 10
- Batch size: 16
- Max length of tokens: 512
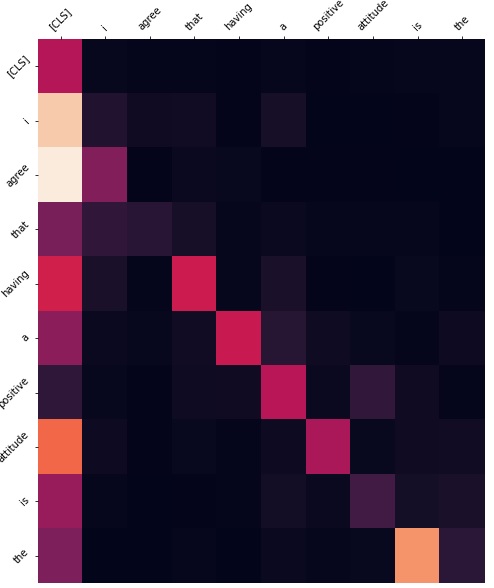
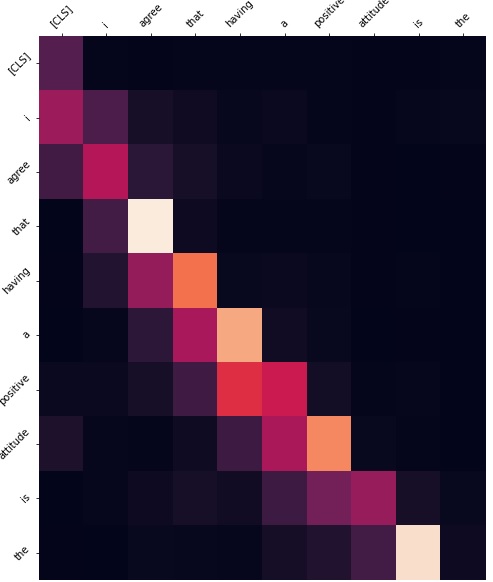
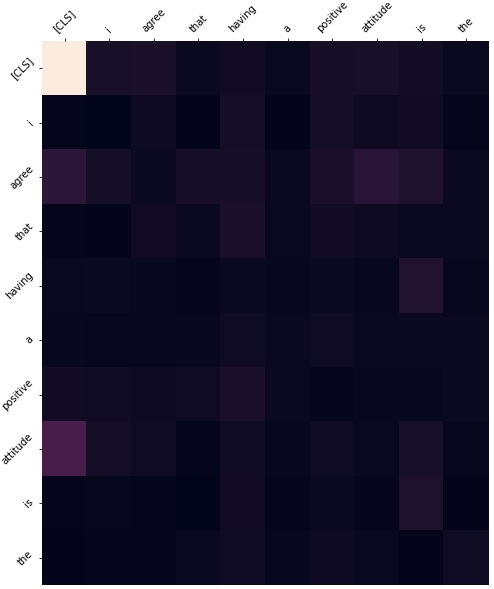
In addition to this, we investigated the attention weights to see which layers we should actually freeze. Freezing all the encoders would cause the results to be almost as if we did no fine tuning at all. This is why it was important to investigate which layers would make sense to actually freeze. As we can see from the figures below, we have shown the layers we felt were most impactful in freezing. If we take a look at layer 3 for example, it seems to be simply paying attention to the next word in the sequence. Layer 1 has the highest activations on connective words which won't be different from what data it was trained on. Layer 4 seems to be paying attention to the CLS token. There is no need to tune this layer either. For example, layer 9 has a very high activation for words which are identifying words. From these observations, we decided that the first 5 layers are attending to features which do not need to be tuned as they are more general. Therefore, in our final model we freeze the first 5 encoder layers by disabling gradient computation. In our results this not only reduced overfitting, but also reduced run time by a very small amount.



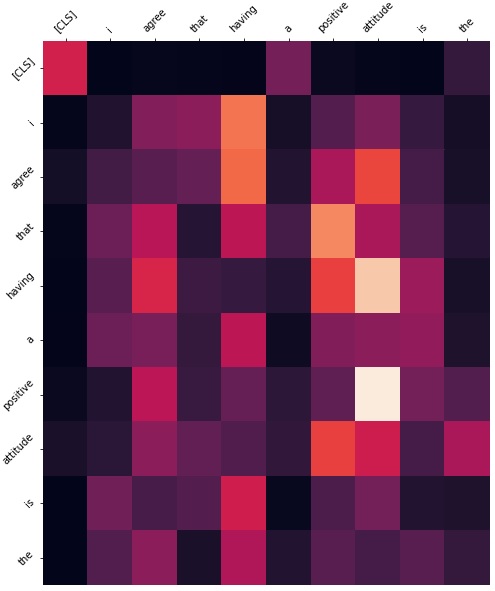
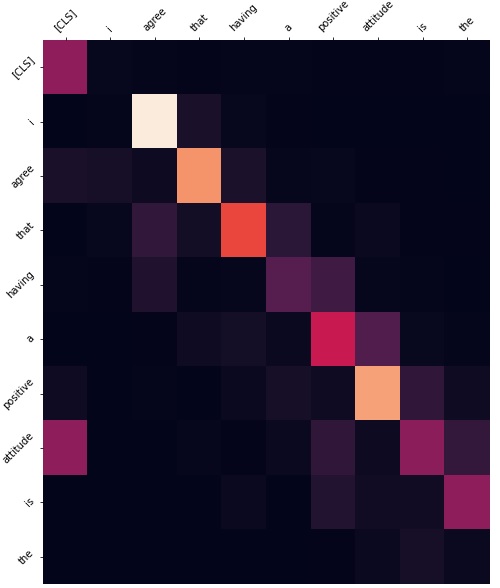
We are using max pooling with our model. The first 5 encoder layers (disabled gradient computation) were frozen and removed ranking layer (No topical features). The scores were normalized between 0 and 1.
Results
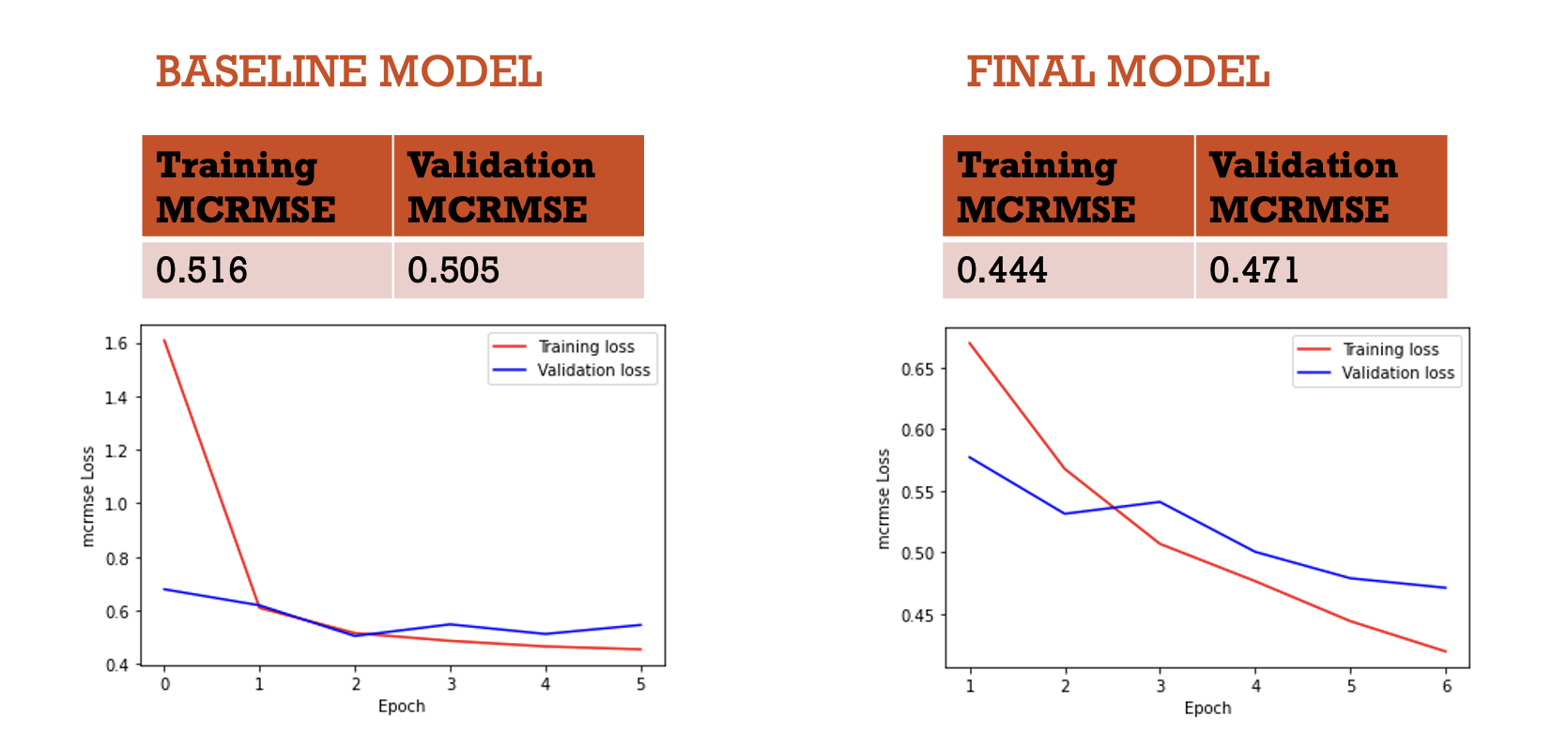
The final model preforms better as compared to the base model. After a few epocs the model starts overfitting and the validation loss starts increasing wheras in the final model the model doesn't overfit.
References
[1] Yang, Ruosong, Jiannong Cao, Zhiyuan Wen, Youzheng Wu, and Xiaodong He. "Enhancing automated essay scoring performance via fine-tuning pre-trained language models with combination of regression and ranking." In Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 1560-1569. 2020
[2] Feedback prize - english language learning. Kaggle. (n.d.). Retrieved September 29, 2022, from https://www.kaggle.com/competitions/feedback-prize-english-language-learning/overview/description
[3] Kumar, V., & Boulanger, D. (1AD, January 1). Explainable automated essay scoring: Deep Learning really has pedagogical value. Frontiers. Retrieved September 29, 2022, from https://www.frontiersin.org/articles/10.3389/feduc.2020.572367/full
[4] Bonthu, S., Rama Sree, S., & Krishna Prasad, M. H. M. (1970, January 1). Automated short answer grading using Deep learning: A survey. SpringerLink. Retrieved September 29, 2022, from https://link.springer.com/chapter/10.1007/978-3-030-84060-0_5
[5] Ramesh, D., & Sanampudi, S. K. (2021, September 23). An automated essay scoring systems: A systematic literature review - artificial intelligence review. SpringerLink. Retrieved September 29, 2022, from https://link.springer.com/article/10.1007/s10462-021-10068-2#:~:text=Automated%20essay%20scoring%20(AES)%20is,(1973).
[6] Yang, R., Cao, J., Wen, Z., Wu, Y., & He, X. (n.d.). Enhancing automated essay scoring performance via fine-tuning pre-trained language models with combination of regression and ranking. ACL Anthology. Retrieved December 13, 2022, from https://aclanthology.org/2020.findings-emnlp.141/
[7] hsm207. (n.d.). Bert_attn_viz/bert_attn_viz at master · HSM207/Bert_attn_viz. GitHub. Retrieved December 13, 2022, from https://github.com/hsm207/bert_attn_viz/tree/master/bert_attn_viz
Team Members and contributions
1. Tanmay Khokle - Development of base and improved model, attention visualization, presentation, report
2. Neha Yadav - Report, data preprocessing and visualization, attention visualization