An Analysis of SO(2) Equivariant Reinforcement Learning
Equivariant neural networks enforce symmetry within the structure of their convolutional layers, resulting in a substantial improvement in sample efficiency when learning an equivariant or invariant function. Such models are applicable to robotic manipulation learning which can often be formulated as a rotationally symmetric problem. This ICLR 22 Spotlight paper studies equivariant model architectures in the context of Q-learning and actor-critic reinforcement learning. We identify equivariant and invariant characteristics of the optimal Q-function and the optimal policy and propose equivariant DQN and SAC algorithms that leverage this structure. We present experiments that demonstrate that our equivariant versions of DQN and SAC can be significantly more sample efficient than competing algorithms on an important class of robotic manipulation problems.
Biography
| Name | Photo | Affiliation | Research Interests | Background |
|---|---|---|---|---|
| Dian Wang |  |
PhD Candidate at Northeastern University | Machine Learning and Robotics, Equivariant ML on Robot Manipulation | MS.CS @ Northeastern University, BS.CS @ Sichuan University, Chengdu, China |
| Robin Walters |  |
Assistant Professor at Northeastern University | Theory of DL through symmetry | Ph.D. Math @ University of Chicago, BA. Math @ Harvard University |
| Robert Platt |  |
Boston Dynamics Artificial Intelligence; Associate Professor at Northeastern University | Robotics, Manipulation, Policy Leraning. | Ph.D. CS @ University of Massachusetts Amherst, BS. EE @ Duke University |
Method and Diagram

This work studies the SO(2) equivariant property of robotic manipulation in the context of reinforcement learning. We use equivariant networks to enforce the equivariance in the structure of the networks to improve the sample efficiency.
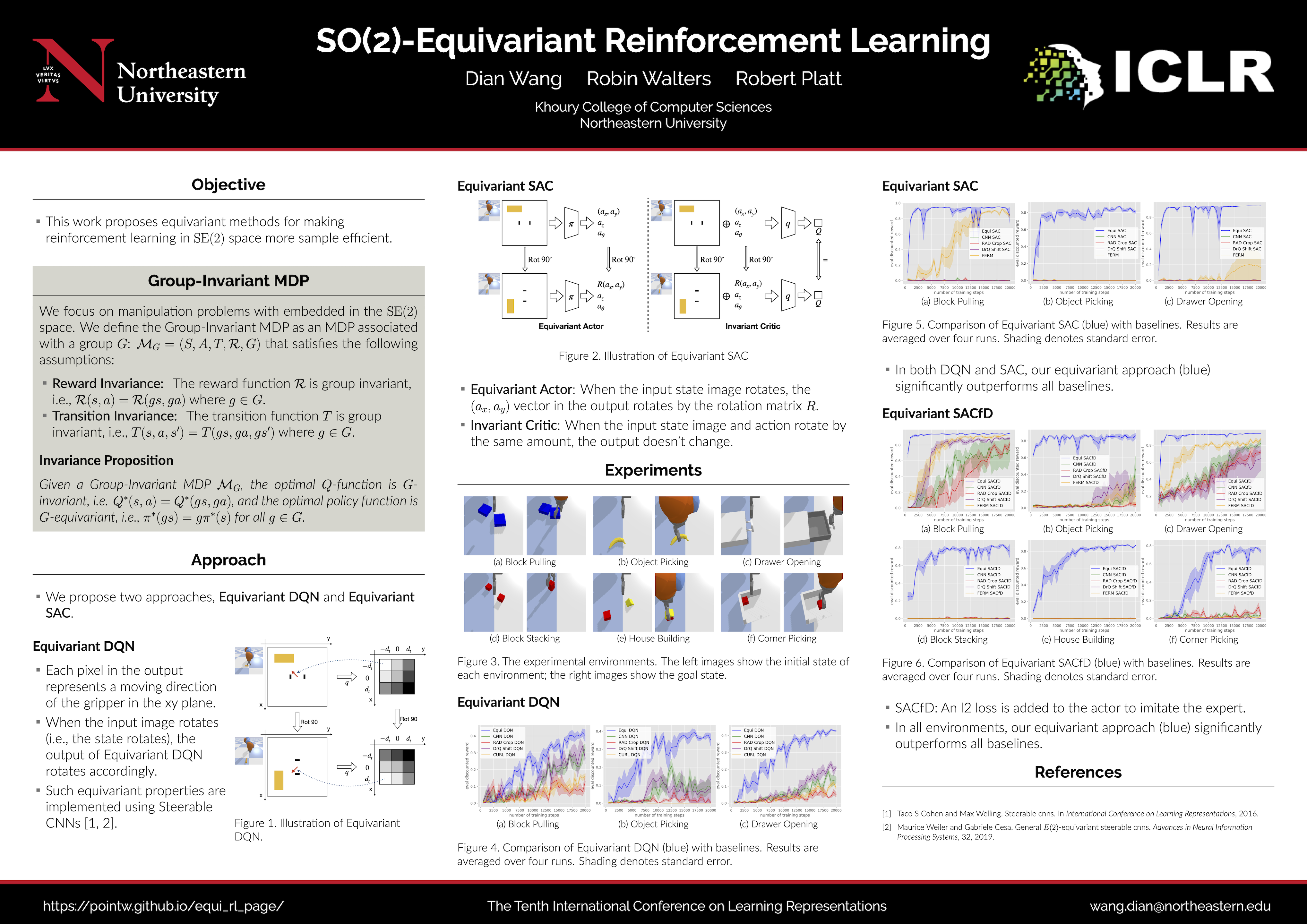
In Equivariant DQN, if the input state of the Q-network is rotated, the output of the Q-network (where the value of each cell in the 3x3 grid represents the Q-value of moving towards a specific direction) will be rotated by the same amount.
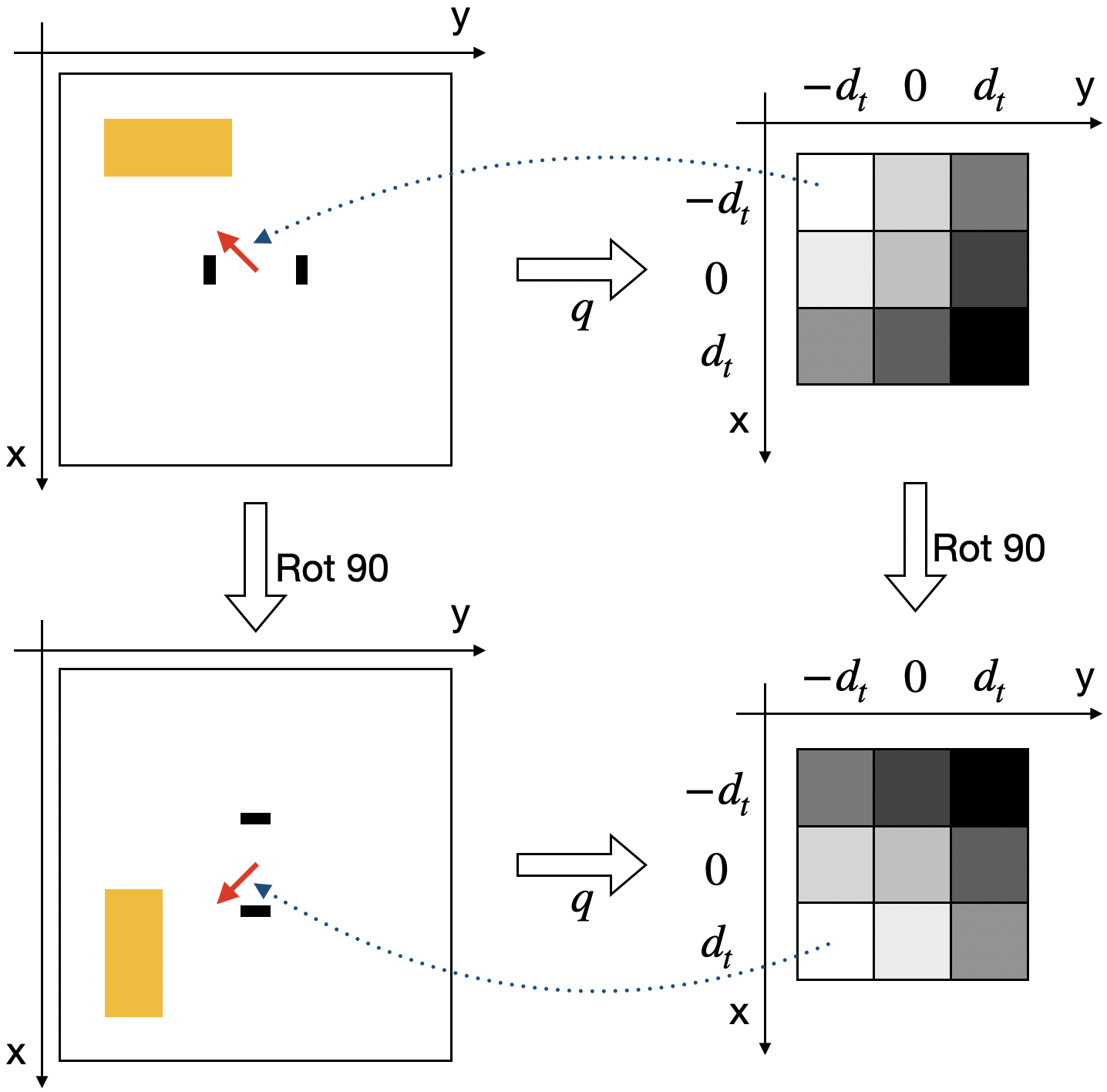
In Equivariant SAC, if the input state of the actor (left) is rotated, the output action of the actor will be rotated by the same amount. If the input state and action of the critic (right) are rotated, the output Q-value of the critic will remain the same.

Object Picking

Block Pulling

Drawer Opening

Block Stacking

House Building

Corner Picking
Our Equivariant SAC can solve different manipulation tasks with high sample effeciency.
Object Picking
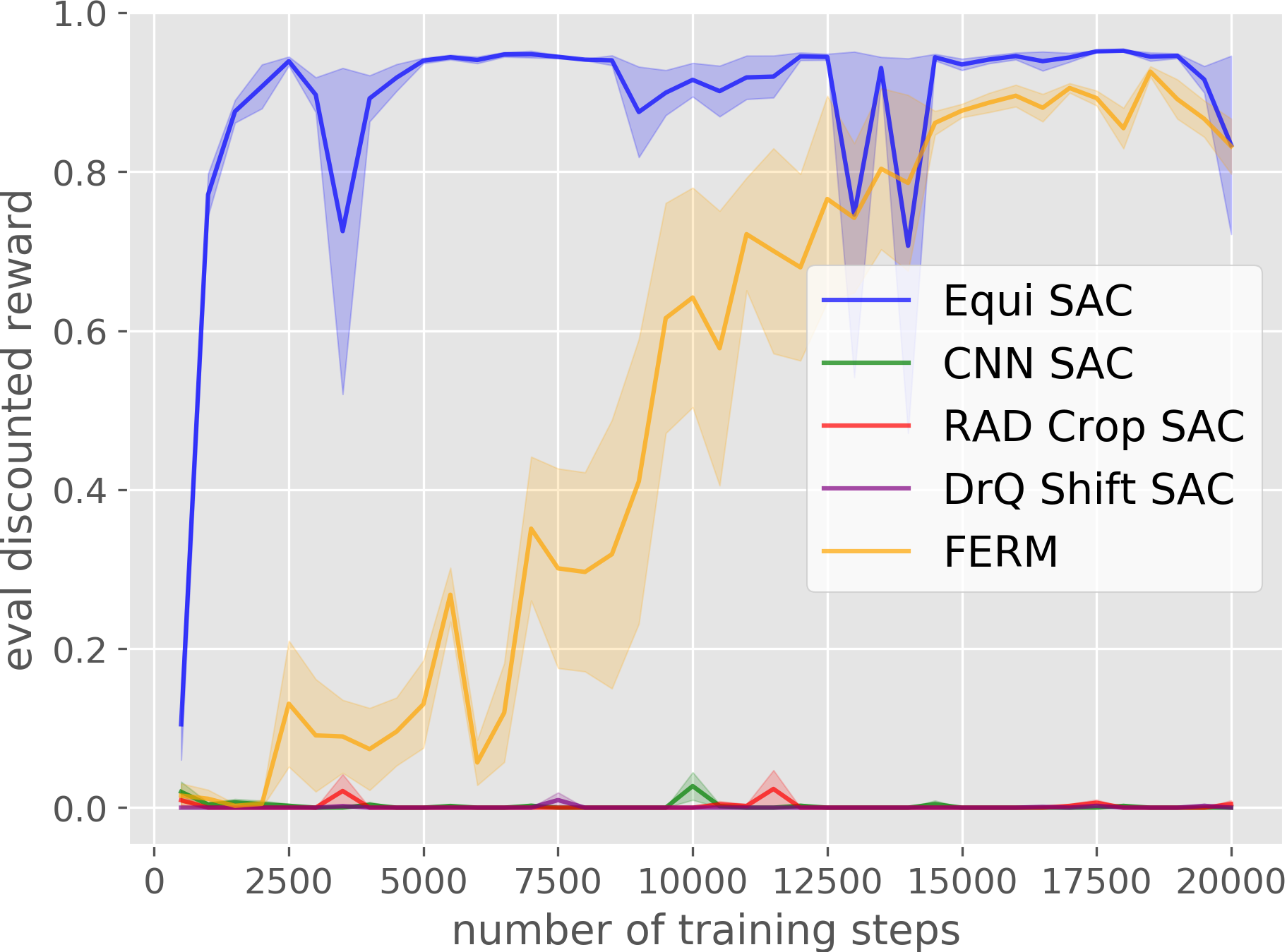
Block Pulling
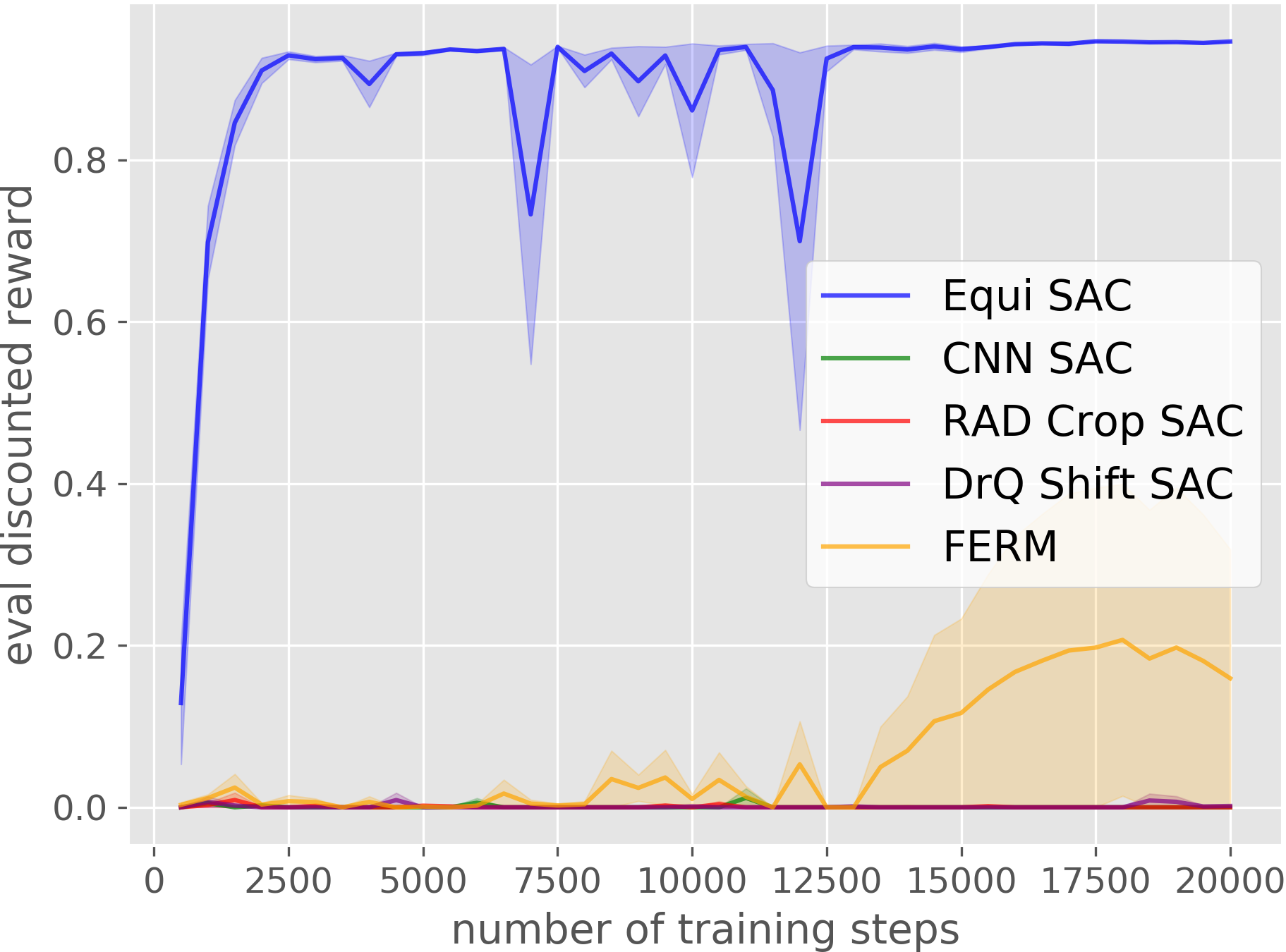
Drawer Opening
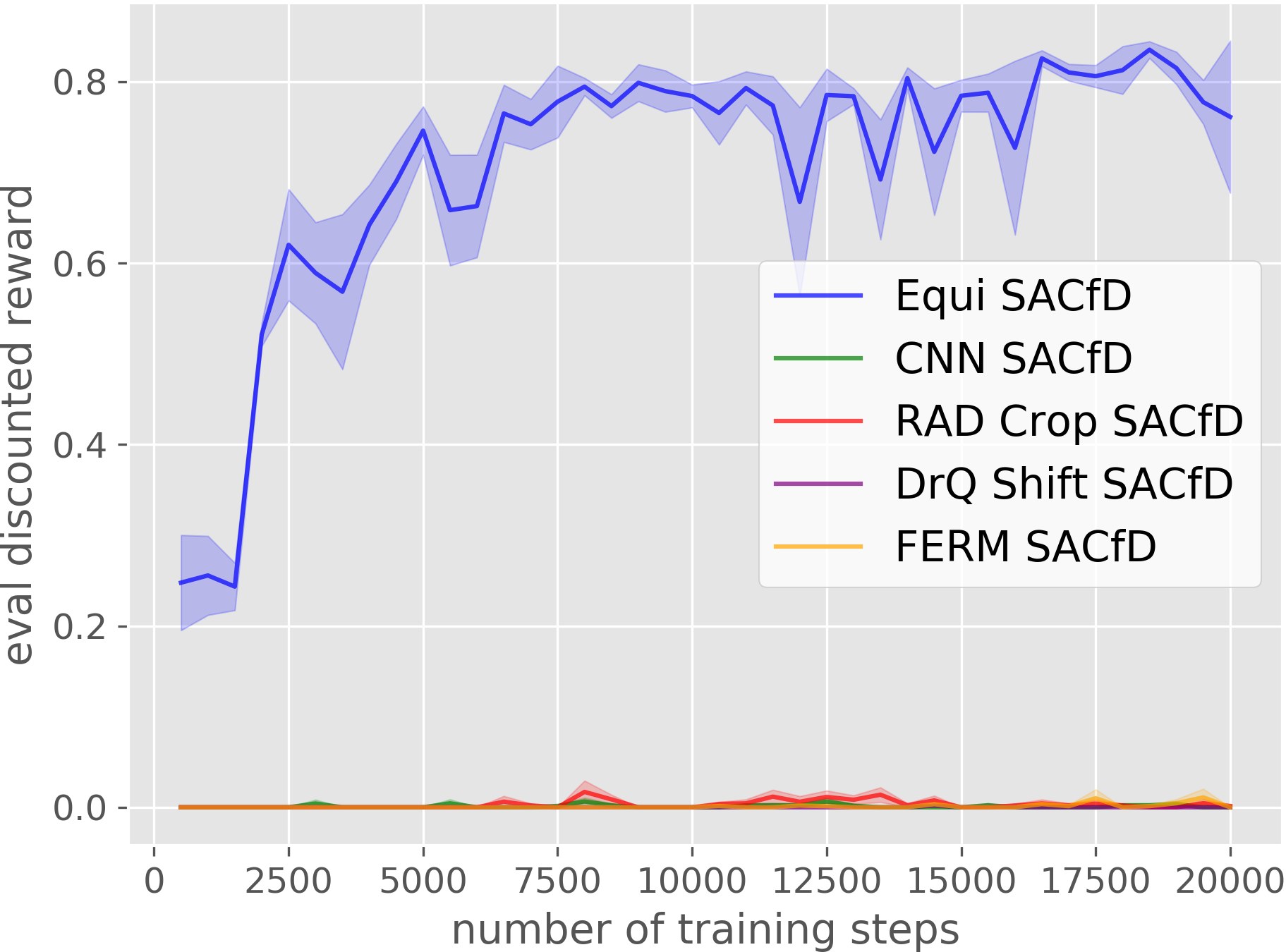
Block Stacking
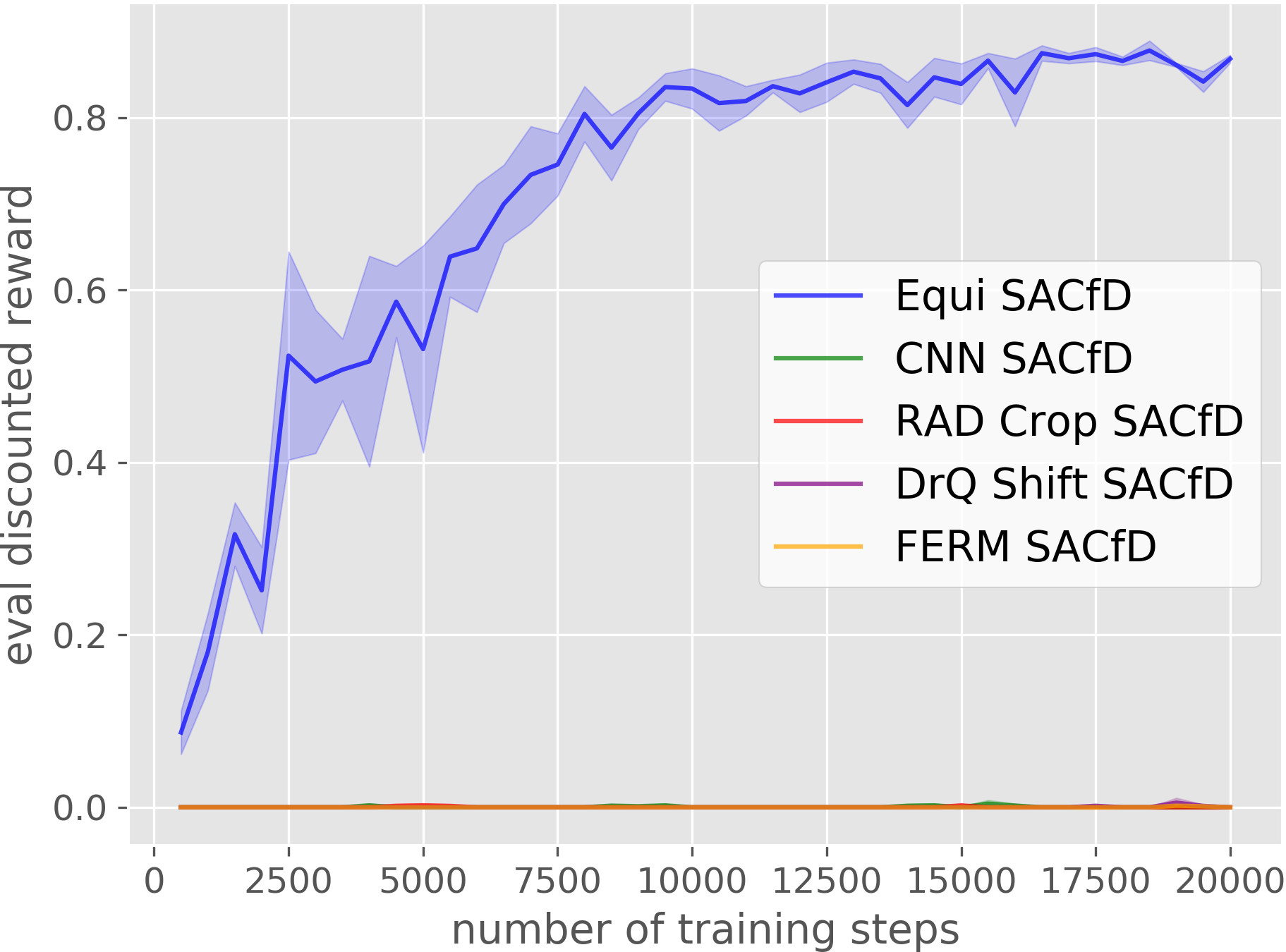
House Building
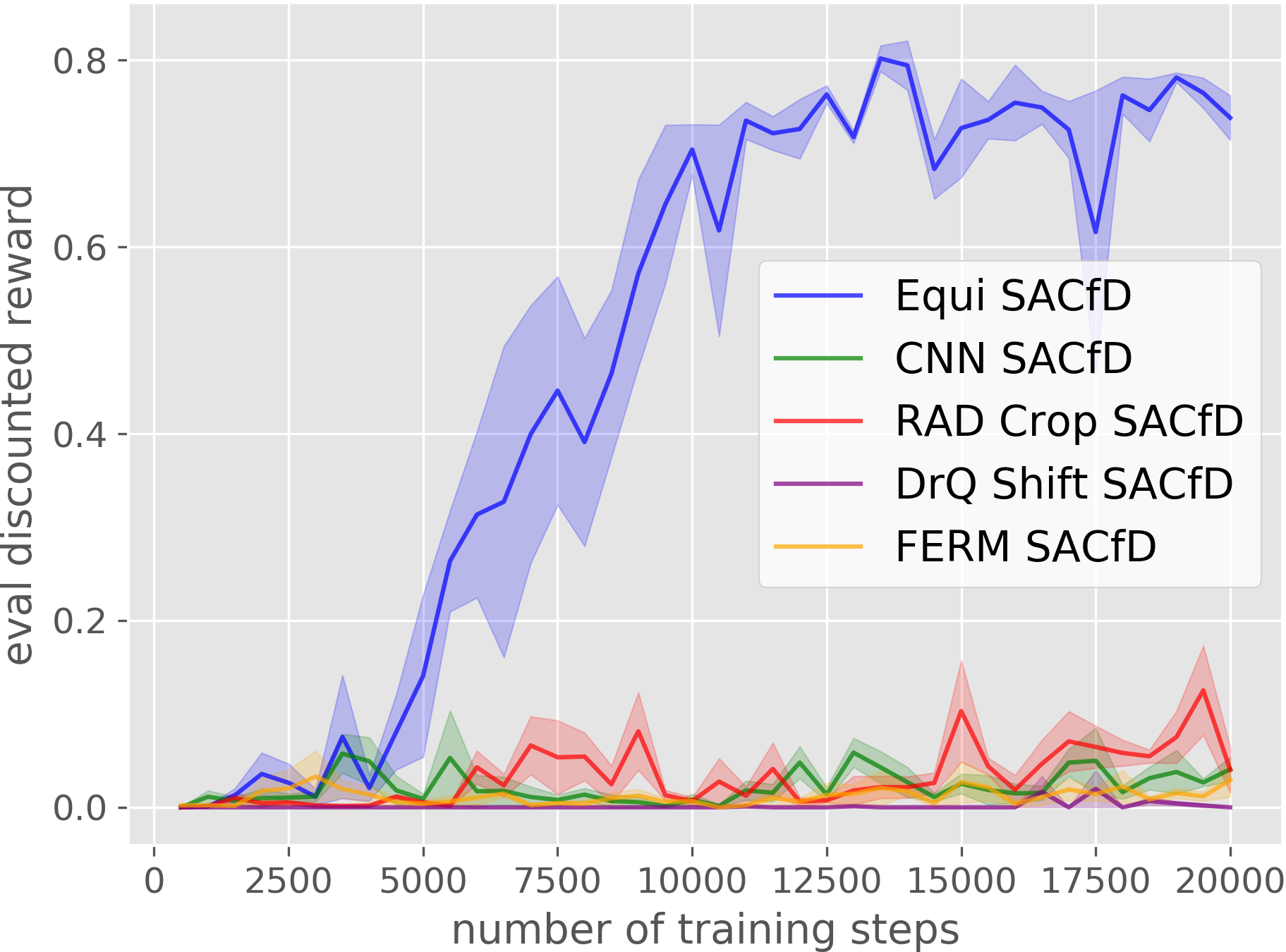
Corner Picking
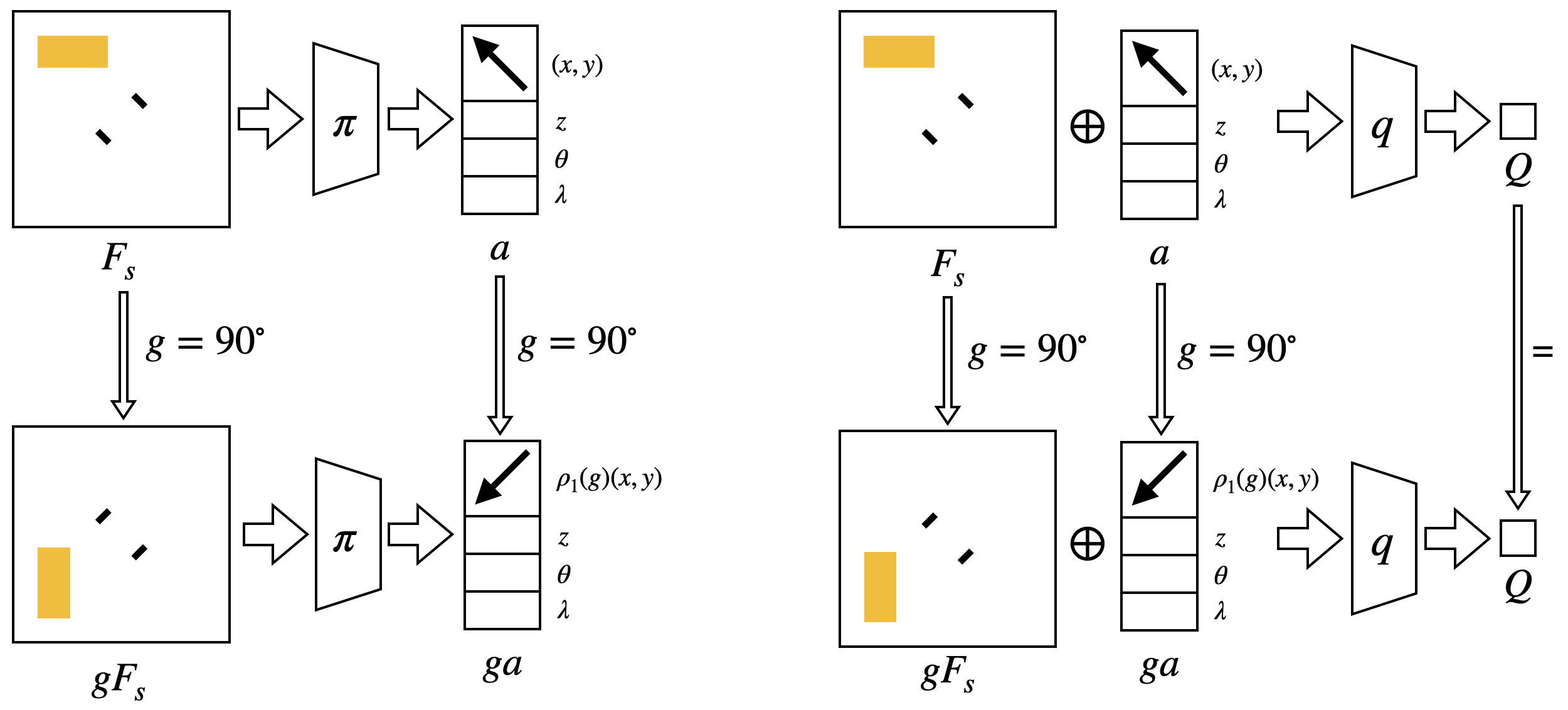
Our Equivariant method (blue) dramatically outperforms competing baselines, including some sample-efficient baselines using data augmentation.
Social Impact
With the help of this more efficient variant of RL, more and more industries can be potentially transformed. When robot manipulators and legged robots become more accessible and efficient, they have the potential to replace large volume of workers in factories. This could lead to increasing unemployment rate and longlasting disturbances in the society, as evidenced by the introduction of robots to for example vehicle assembly lines. But in the long run, possibly with the bias of an AI researcher, this is a beneficial change: more and more education and resources will be skewed toward the scientific frontier -- as human beings are no longer required to learn repetitive tasks -- and help us explore regions, tasks, and fields that seems infeasible to us today. I have seen lots of brilliant minds tightening screws in assembly lines in China, and their intellectual ability should not be restrained and wasted in tasks where human are less efficient and far less accurate than robots.
Industry Application and Impact
Reinforcement Learning algorithms have suffered from the need of large volume of interaction with the simulated/real world environment. Although there exist various research on generalizing existing models to new tasks, the generalizing performance of RL models are still far from mass deployment to real world robots. Among the first papers to bridge together Reinforcement Learning and Equivariant neural networks, this work significantly improved the sample efficiency of Reinforment Learning algorithms on robot manipulation tasks. This is a big step toward deployable and scalable robot manipulators for use in various scenarios. For example, assembly line factories, health care, millitary, and so on. A general purpose Reinforcement Learning algorithm for manipulation task can be imagined if the generalizability of such algorithms can be improved -- robot manipulation world can see some hope for their own Chatgpt.
Follow-on Research
This paper is one of the first to embed the equivariance property in the reinforcement learning and robot manipulation tasks. Inspired by this paper, lots of good papers have been published. For instances, [2] Sample Efficient Grasp Learning Using Equivariant Models. Xupeng Zhu, Dian Wang, Ondrej Biza, Guanang Su, Robin Walters, Robert Platt Robotics: Science and Systems (RSS). [3] Equivariant Transporter Network. Haojie Huang, Dian Wang, Robin Walters, Robert Platt Robotics: Science and Systems (RSS). [4] Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction David M. Klee, Ondrej Biza, Robert Platt, Robin Walter International Conference on Learning Representations (ICLR) Recently, some following works have applied this idea to the more complex SE(3) space, achieving good performance and sample efficiency in that field. Also, by combining the equivariance algorithm with the large pre-trained model, like chat-gpt, segment anything, etc., some researchers are studying the sample efficiency, performance, and generalization of the model to see whether it can be further improved.
Review
The research investigates the application of equivariant neural network architectures in model-free reinforcement learning for visuomotor robot manipulation tasks. The goal is to enhance sample efficiency by leveraging rotational symmetries. The paper begins by formally defining and theoretically evaluating a category of Markov Decision Processes (MDPs) termed "group-invariant MDPs," where rewards and transitions are invariant to group elements. It then introduces equivariant versions of popular reinforcement learning algorithms, namely DQN, SAC, and learning from demonstration (LfD). Experimental results across various manipulation tasks demonstrate that the proposed architectures outperform current benchmarks in terms of sample efficiency and generalization. Ablation studies further highlight the contribution of individual model components. The concept of structuring neural architecture to exploit domain symmetry for improved sample efficiency is both compelling and well-founded. The paper's contributions are twofold: firstly, it introduces an effective variation of equivariant DQN tailored for challenging and realistic visuomotor control domains. Secondly, it puts forth novel equivariant versions of SAC and LfD, substantiating their efficacy through comprehensive experiments. Therefore, I concur with the paper's significance and overall value.
References
[1] Dian Wang, Robin Walters, and Robert Platt. SO(2) Equivariant Reinforcement Learning. International Conference on Learning Representations 10 (2022) Spotlight Presentation.
[2] Xupeng Zhu, Dian Wang, Ondrej Biza, Guanang Su, Robin Walters, Robert Platt. Sample Efficient Grasp Learning Using Equivariant Models. Robotics: Science and Systems (RSS).
[3] Haojie Huang, Dian Wang, Robin Walters, Robert Platt Equivariant Transporter Network. Robotics: Science and Systems (RSS).
[4] David M. Klee, Ondrej Biza, Robert Platt, Robin Walter Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction International Conference on Learning Representations (ICLR)
Team Members
Boce Hu and Zihao Dong