An Analysis of Playing Atari With Deep Reinforcement Learning
Revolutionizing the field of Reinforcement Learning by combining existing methods with Deep Learning networks on raw sensory input.
Paper Overview
The 2013 research paper "Playing Atari with Deep Reinforcement Learning" by Mnih et al. not only introduced a groundbreaking deep learning model but also showcased the broad applicability of deep reinforcement learning across various domains. The following figure provides a snapshot of these diverse applications.
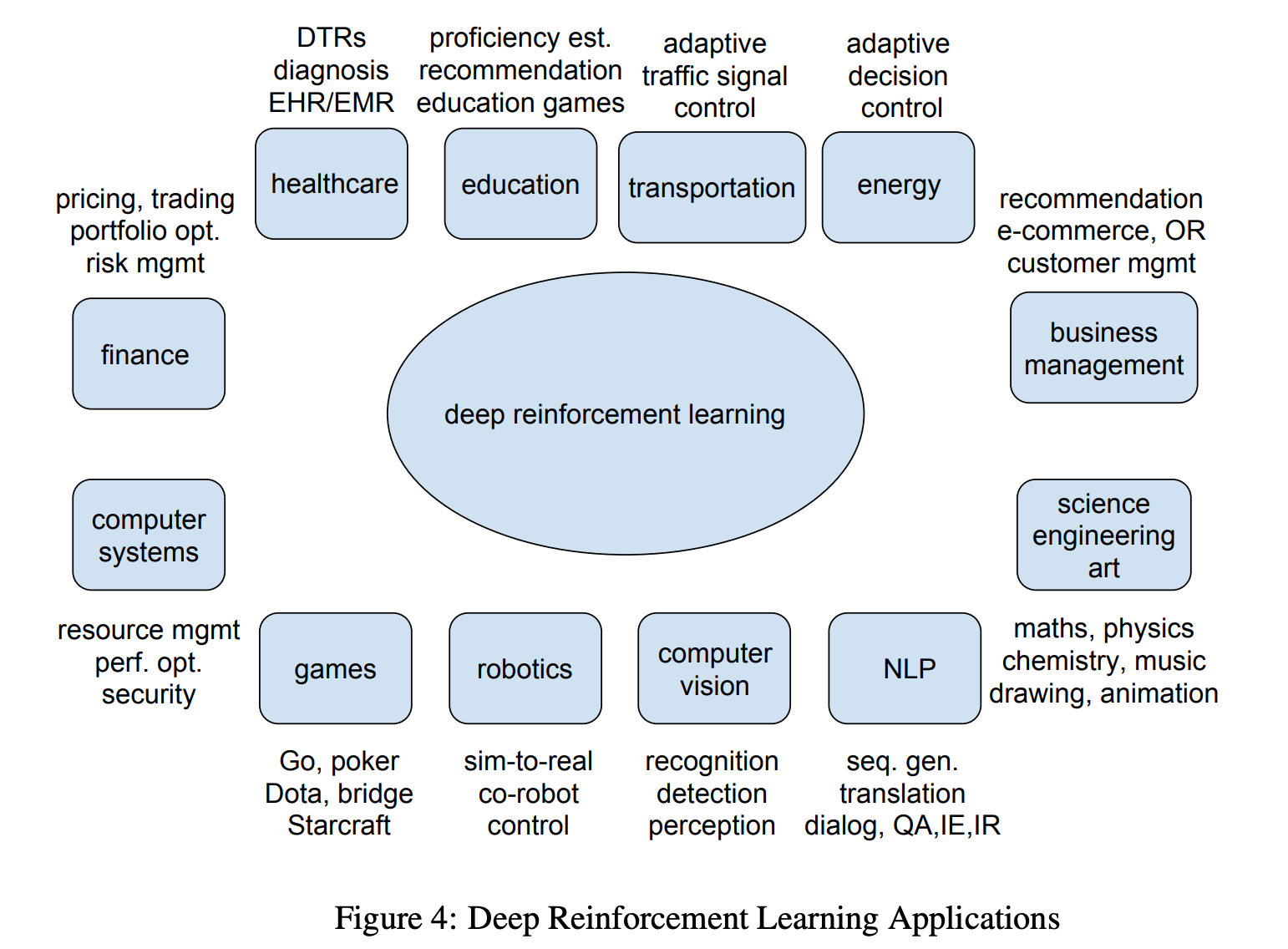
This illustration depicts the wide-ranging impact of deep reinforcement learning, from healthcare and education to more complex tasks such as autonomous driving and robotics. It sets the stage for understanding the transformative potential of the research presented in the paper.
Literature Review
The development of deep reinforcement learning, as showcased in this paper, is built upon earlier significant works. Pioneering algorithms like TD-gammon by Gerald Tesauro and Neural Fitted Q-learning (NFQ) by Martin Riedmiller laid the groundwork for this field. Additionally, the Arcade Learning Environment, developed by Marc Bellemare and others, provided a standard testing platform for reinforcement learning algorithms on Atari 2600 games. These foundational works were crucial for the advancements made in "Playing Atari with Deep Reinforcement Learning."
Methodology and Technical Details
The cornerstone of the research presented in "Playing Atari with Deep Reinforcement Learning" is its innovative network architecture. The model is a convolutional neural network (CNN), designed specifically to process and interpret the visual input from Atari games.
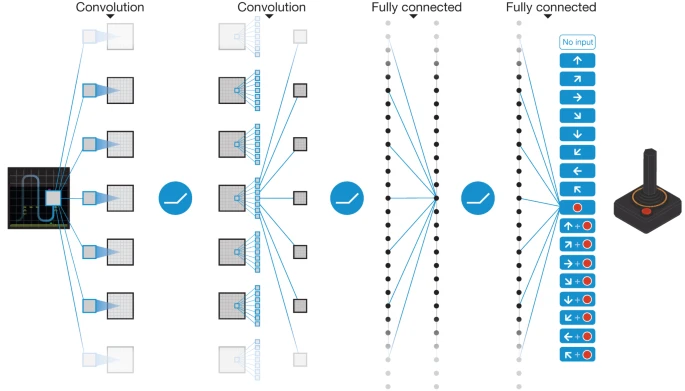
The architecture comprises three convolutional layers and two fully connected layers. The network processes input in the form of an 84x84x4 image, which is derived from preprocessing the raw frames of Atari 2600 games. Here's a breakdown of the layers:
- First Hidden Layer: This layer applies 16 8x8 filters with a stride of 4 to the input image. Following the convolution, a rectifier nonlinearity is applied.
- Second Hidden Layer: This layer consists of 32 4x4 filters with a stride of 2, again followed by a rectifier nonlinearity.
- Third Hidden Layer: The final hidden layer is fully connected, containing 256 rectifier units.
- Output Layer: The output is a fully-connected linear layer, corresponding to each valid action in the game. The number of valid actions varies between 4 and 18, depending on the game.
Understanding Q-Learning and Deep Q-Learning
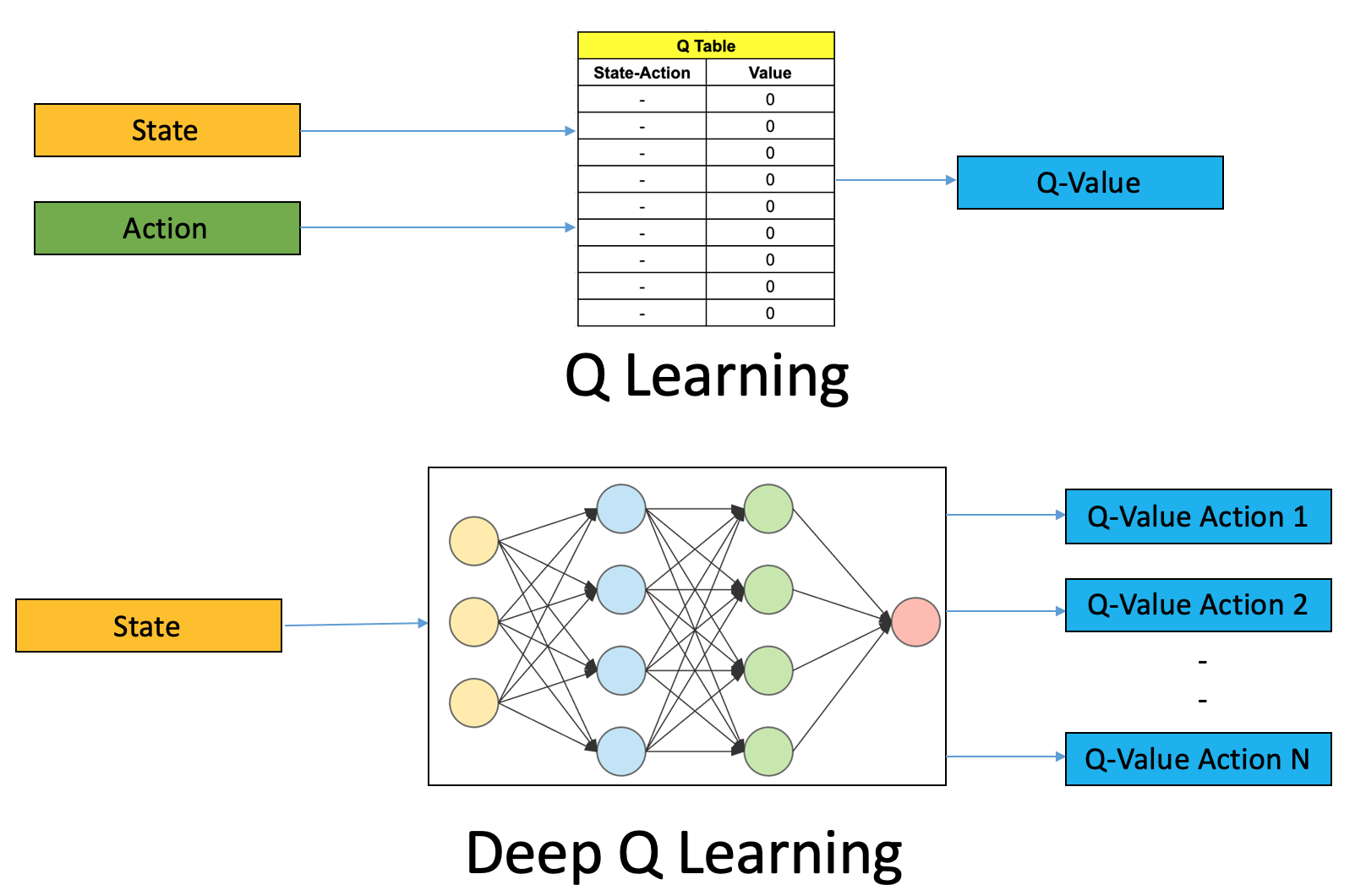
This image contrasts the traditional Q-learning algorithm with Deep Q-learning. Q-learning works by updating a table of values (Q-table) that estimate the reward for each action in every state. However, as the number of states grows, Q-learning becomes impractical. Deep Q-learning solves this by using a neural network to approximate the Q-values for each action, without needing a massive Q-table, enabling it to handle environments with high-dimensional state spaces such as video games. In this graph each node represents a state in the environment while each connection between the nodes represents an action that one can take between each state. This is where the Q values come in as they are the weights for each of these connections that allow the network to choose the optimal next step.
Algorithm 1: Deep Q-learning with Experience Replay

This algorithm is a crucial part of the paper's methodology. It outlines the process of deep Q-learning combined with experience replay, a technique that significantly improves the learning efficiency of the neural network. By storing past experiences and randomly sampling from this memory, the network can learn from a diverse range of past scenarios, leading to more robust learning outcomes. This approach addresses the issue of correlated data and non-stationary distributions, common challenges in deep reinforcement learning.
Performance Evaluation
The following table provides a comparative analysis of the performance of various learning methods, including Deep Q-Learning, on a selection of Atari games. These games serve as benchmarks to evaluate the efficacy of the models.

The upper table presents average total rewards for a fixed number of steps across different learning methods. Notably, the Deep Q-Learning model outperformed a human expert in games such as Breakout, Enduro, and Pong and was competitive in Beam Rider. However, human players still excelled in Q*bert, Seaquest, and Space Invaders. These games pose a greater challenge as they require the development of long-term strategies, highlighting the variance in complexity and objectives among the 2600 Atari games used in this extensive and diverse testing environment.
Biography
The authors of "Playing Atari with Deep Reinforcement Learning" are a team of renowned researchers from DeepMind Technologies. Each member brings a unique set of skills and experiences, contributing to the groundbreaking nature of this research. The team's diverse academic and professional backgrounds in AI and machine learning have been instrumental in advancing the field. Below is a brief overview of each author and their contributions to the paper.
 |
Volodymyr Mnih: PhD in Machine Learning from the University of Toronto and a Master's degree in computing science from the University of Alberta. |
 |
Koray Kavukcuoglu: VP of Research at DeepMind, previously at NEC Labs America. PhD from New York University, with a background in aerospace engineering. |
 |
David Silver: Principal Research Scientist at DeepMind and professor at University College London, contributing significantly to AI research. |
 |
Alex Graves: Research Scientist at DeepMind, holding a BSc in Theoretical Physics from the University of Edinburgh and a PhD in artificial intelligence. |
 |
Ioannis Antonoglou: Software Engineer at Google DeepMind, with an engineer's degree in electrical and computer engineering and an M.Sc. in artificial intelligence and machine learning. |
:format(webp)/s3/static.nrc.nl/images/stripped/1006hgv_voorfoto.jpg) |
Daan Wierstra: Principal Scientist at DeepMind, specializing in scientific roles and research in AI. |
 |
Martin Riedmiller: Team Lead at DeepMind, focused on the development of intelligent machines learning new concepts autonomously. |
Social Impact
The research in "Playing Atari with Deep Reinforcement Learning" has significant implications for society, both positive and negative. This section explores these impacts in more detail.
Positive Impact
- Education and Training: AI-driven educational tools can personalize learning, adapting to individual student needs and enhancing educational outcomes.
- Healthcare Enhancements: AI applications in healthcare could lead to more accurate diagnoses and personalized treatment plans.
- Environmental Monitoring: AI can be used in environmental conservation efforts, such as wildlife monitoring and climate change analysis.
Negative Impact
- Privacy Concerns: Increased use of AI in surveillance and data analysis could lead to privacy intrusions.
- Disinformation Spread: AI-generated content could be used to create and spread false information, impacting public discourse.
- Ethical Dilemmas: AI decision-making in areas like law enforcement or healthcare raises ethical questions about fairness and accountability.
Industry Applications
The methodologies introduced in "Playing Atari with Deep Reinforcement Learning" have far-reaching applications across various industries. This section outlines some key areas where these advancements can be applied.
- Entertainment and Media: AI can be used to create more engaging and interactive media content, including dynamic video games and personalized streaming services.
- Supply Chain Optimization: AI can improve logistics and supply chain management, leading to more efficient distribution systems.
- Customer Service Automation: Chatbots and virtual assistants can provide more efficient and personalized customer support.
- Agricultural Automation: AI-driven solutions can optimize farming techniques, leading to increased crop yields and sustainable practices.
- Energy Management: AI can enhance energy efficiency in various sectors by optimizing usage and predicting demand.
Follow-on Research
The groundbreaking work in "Playing Atari with Deep Reinforcement Learning" opens up numerous possibilities for future research in various domains. This section outlines potential directions for such research.
- Complex Game Environments: Exploring the application of deep reinforcement learning in more complex, modern game environments to test and refine AI adaptability and learning capabilities.
- Real-world Simulations: Applying these techniques to simulated real-world scenarios, such as urban planning and disaster response simulations, to enhance decision-making algorithms.
- Human-AI Interaction: Investigating how AI trained through reinforcement learning can interact more naturally and effectively with humans in various contexts, including education, healthcare, and customer service.
- AI Ethics and Governance: Researching the ethical implications and necessary governance frameworks for advanced AI systems to ensure responsible and beneficial use.
- Interdisciplinary Applications: Combining deep reinforcement learning with other fields like neuroscience and psychology to develop AI that mimics human learning and cognitive processes more closely.
Peer Review
Chase Kenyon
Score: 7/10 - The paper excels in merging deep learning with reinforcement learning, a leap forward for AI capabilities with high-dimensional data. It showcases the practicality of reinforcement learning in broader applications. However, the reliance on large datasets and computational resources poses limitations for wider adoption.
Nicholas Calvaresi
Score 7/10 - The paper used a very revolutionary idea in Q-learning and explored more about this topic and deep reinforcement learning. They were able to build a model that outperformed previous approaches in 6 of the games as well as outperformed a human expert in three games. This led to further exploration and research into AI. However it didn’t really explore anything new. There was an article written earlier this year that they just built upon their findings and improved their models.
References
- Mnih, V., et al. (2013). Playing Atari with Deep Reinforcement Learning. NIPS Deep Learning Workshop, 2013.
- Tesauro, G. (1995). TD-Gammon: A Self-Teaching Backgammon Program. Semantic Scholar.
- Riedmiller, M. (2005). Neural Fitted Q Iteration - First Experiences with a Data Efficient Neural Reinforcement Learning Method. Semantic Scholar.
- Bellemare, M., et al. The Arcade Learning Environment: An Evaluation Platform for General Agents. Ar5iv.
Team Members
Chase Kenyon, Nicholas Calvaresi.