An Analysis of Language Models are Unsupervised Multitask Learners
Examining a paper demonstrating the ability of large scale language models (GPT-2) to complete zero shot task transfer, a foundational property of subsequent GPT-3.5 and GPT-4 models.
Literature Review
- Word Embeddings (2013): Mikolov et al. (2013) and Pennington et al. (2014) introduced Word2Vec and GloVe embeddings, revolutionizing word representation in continuous vector spaces for better generalization.
- Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) Networks (2014): Sutskever et al. and Cho et al. (2014) advanced Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) Networks, enhancing sequential dependency capture for tasks like language modeling and machine translation.
- Attention Mechanism (2017): The introduction of attention mechanisms, as seen in the Transformer architecture by Vaswani et al, revolutionized sequence-to-sequence tasks. The self-attention mechanism allowed models to focus on different parts of the input sequence when making predictions, leading to improved performance.
- The Goldilocks Principle: Reading Childrens Books with Explicit Memory Representations (2017): This paper explored the idea of utilizing explicit memory representations to improve language understanding. It contributed to the understanding of how memory mechanisms can enhance NLP tasks.
- Transfer Learning in NLP (2018): Researchers started leveraging transfer learning in NLP, pre-training models on large datasets for general language understanding tasks and then fine-tuning them for specific tasks. OpenAI's GPT (Generative Pre-trained Transformer) was a notable example of this trend.
- Exploring the Limits of Language Modeling (2018): This paper by. OpenAI contributed insights into the scaling of language models, showing that larger models trained on massive datasets could achieve better performance. The findings in this paper set the stage for the development of even more advanced models like GPT-2 and GPT-3.
- BERT (Bidirectional Encoder Representations from Transformers) (2018): Google's BERT introduced bidirectional context representation. It popularized the use of large-scale pre-training on massive corpora, showcasing the effectiveness of unsupervised learning for language understanding.
Biography
Alec Radford
- The original paper on generative pre-training of a transformer-based language model was written by Alec Radford (GPT-1)
- Franklin W. Olin College of Engineering
- Head of research at indico data solutions
- ML developer/researcher at OpenAI
- 104767 citations

Jeffrey Wu
- MIT Undergraduate
- MIT Masters in Probabilistic Programming Languages
- 2nd employee at startup Terminal.com, left after 4 years and Terminal was later acquired by Udacity
- 2 years at Google working on deep learning for user personalization
- Now at OpenAI on the alignment team, working to ensure that AI is truthful and helpful
- 40650 citations
- Website

Rewon Child
- 2022 - Present: Founding team, Member of Technical Staff at Inflection
- 2021 - 2022: Research at Google Brain/Search on large models.
- 2018 - 2020: Algorithms team at OpenAI
- 2016 - 2017: Speech team at Andrew Ng's lab at Baidu Research.
- 2015 - 2016: Enlitic, a startup focused on applying deep learning to medical imaging.
- 44589 citations
- Website

David Luan
- VP of engineering at OpenAI
- Most of his career has revolved around near- and long-term impacts of AI on society
- Certificate in CS from Worcester State, and a BS/BA in Applied Math and Political Science from Yale
- Former director of AI at Axon
- Founded and was CEO of Dextro
- 11276 citations
- Website

Dario Amodei
- CEO and Co-founder of anthropic, AI safety and research company
- Quit OpenAI to build rival company in 2020
- Was VP of research, research director, and team lead for AI safety
- Senior Research scientist at google
- Research Scientist at Baidu Inc with Andrew Ng
- Undergraduate from Stanford in Physics
- PhD from Princeton in Biophysics
- 44885 citations

Ilya Sutskever
- Co-founder and chief scientist at OpenAI
- Co-inventor, with Alex Krizhevsky and Geoffrey Hinton, of AlexNet, a convolutional neural network
- Co-author of the AlphaGo paper
- Postdoc with Andrew Ng at Stanford University
- Joined Hinton's new research company DNNResearch, acquired by Google
- Worked on Tensorflow
- 450860 citations
- Wikipedia

Social Impact
As the zero-shot task transfer ability of large-scale language models discovered in this paper became the backbone for GPT-3.5 and GPT-4, the social impact of this paper can be tied to the social impact of these later models. Many have raised concerns about GPT and other models' potential to replace human jobs and thus leave many people unemployed. As these models evolve, there is potential to use these models to generate misinformation as in the case of fake news and malicious content raising ethical considerations.
A potential positive social impact is by offloading repetitive uncreative work to an AI; it leaves humans more free to spend time and mental energy on creative and innovative work. The free nature of GPT 3 also provides a writing, coding, and useful tool in many other areas to anyone who has access to a computer, which has a potential equalizing factor in opportunity.
Industry Applications
- Text Generation:
- Content Creation for Marketing and Advertising: GPT-2 could be used to automatically generate marketing copy, advertising content, or product descriptions. It could tailor the language and tone based on specified guidelines, allowing businesses to automate the creation of engaging and persuasive content.
- E-learning and Education: GPT-2 could assist in creating diverse and contextually appropriate quiz questions for educational platforms, aiding in the development of interactive learning materials.
- Gaming and Virtual Environments: GPT-2 can contribute to generating dialogue, narratives, and immersive storylines in video games, virtual reality environments, and other digital interactive experiences.
- Chatbot Development:
- Text Summarization
Customer Support and Service: GPT-2 could power a chatbot that provides detailed and contextually relevant responses to customer queries, improving the quality of automated technical support.
Healthcare: GPT-2 could be used to generate concise and understandable summaries of medical documents or research papers, making healthcare information more accessible.
Follow-up Research
Why is it important from an academic point of view?
This paper is important academically because it demonstrates the ability of a large-scale language model to learn not only on the tasks it was trained on but other tasks that it was not been trained on, i.e., zero-shot task transfer. This was done without any explicit supervision and accounted for memorization in the training data set. This was the first time that such a large scale of transferable learning between various tasks without supervision was discovered, and it was done without changing the model from task to task but simply by utilizing a large data set. The discovery of this property would become the critical foundation for GPT-3.5 and other large-scale language models.
Future academic research directions
The authors realize the limitations of GPT-2 in terms of practicality, and that it did a poor job on summarization. The authors also mainly tested GPT-2's performance on NLP tasks but acknowledge that there are many other tasks on which GPT-2 could be evaluated on. The authors also highlight the potential of improvement of performance of GPT-2 with further fine-tuning. As we now know with GPT-3.5 and GPT-4 further research was eventually conducted by changing the model and training it on an even larger data set. Further research can also be conducted on the various parts of the architecture and what contributes to this zero-shot task transfer, as this paper mainly evaluated the performance of the model and did not go into detail about what specifically about the large-scale language model allowed it to complete these tasks.
Peer Review
Summary
The paper presents GPT-2, a large-scale unsupervised language model capable of performing multiple natural language processing tasks without task-specific training. GPT-2 is trained on a diverse range of internet text and uses a transformer architecture to generate coherent and contextually relevant text. Unlike traditional models that are trained for specific tasks, GPT-2 demonstrates the ability to generate high-quality text across various tasks, including language translation, summarization, and question-answering. The model's unsupervised learning approach allows it to generalize well to different domains and tasks, showcasing its versatility as a multitask learner. The paper discusses the model's strengths, such as its ability to capture long-range dependencies in text, as well as its limitations and future research directions.
Strengths and Weaknesses
- Originality: While GPT-2 is based on the architecture of GPT-1, the discovery that large scale language models can do zero-shot task transfer unsupervised was an original and novel discovery.
- Quality: The submission is technically sound and demonstrates the model's ability through several NLP tasks.
- Clarity: The paper is clearly written.
- Significance: The discovery of this new ability of large language models is highly significant and eventually became the foundation for GPT-3.5 and GPT-4.
Limitations
Authors address their limitations (see Further Research section of the blog).
Review Ratings
- Soundness: 4 (Excellent)
- Presentation: 4 (Excellent)
- Contribution: 4 (Excellent)
- Overall: 8 (Strong Accept)
- Confidence: 3 (You are fairly confident in your assessment.)
Diagrams
Diagram 1
We observe a consistent improvement in zero-shot performance across various NLP tasks as the number of parameters in the GPT-2 model increases. This suggests that enlarging the size and capacity of the language model enhances its ability to learn relevant features during pre-training. While the GPT model may not reach the performance levels of some specific tasks achieved by other models, its impressive performance is noteworthy, especially considering its understanding of text without task-specific fine-tuning.
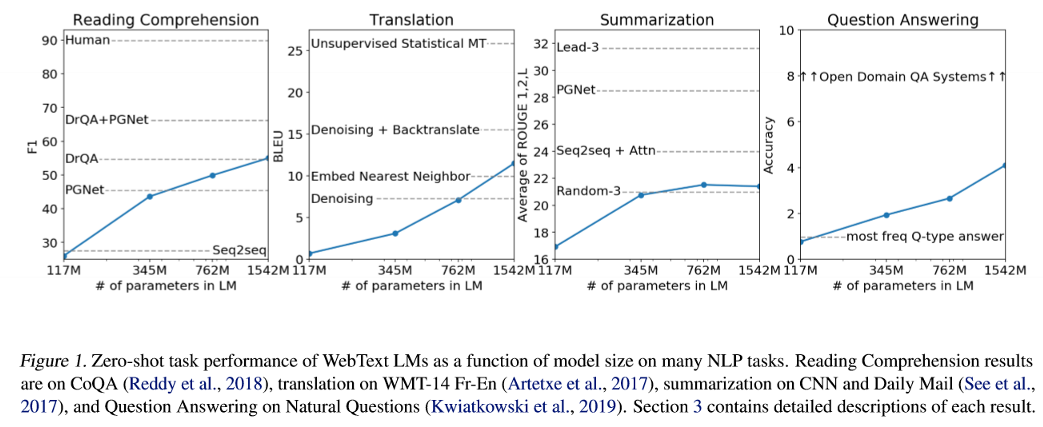
Diagram 2
The fig shows GPT-2 model performance steadily increases, achieving new state-of-the-art results on common nouns (93.3%) and named entities (89.1%) in the CBT. The Childrens Book Test (CBT) assesses language model performance across various word categories, including named entities, nouns, verbs, and prepositions to predict the correct option among 10 choices for an omitted word.
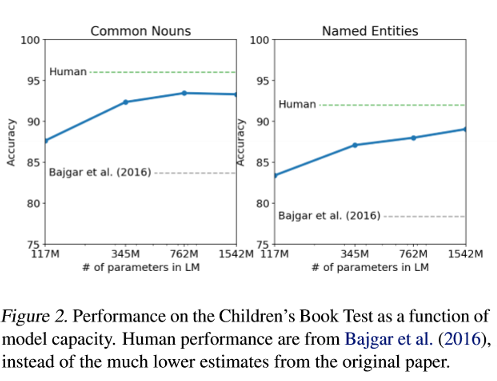
Diagram 3
The Winograd Schema challenge evaluates systems for commonsense reasoning by assessing their ability to resolve ambiguities in text.GPT-2 achieves a state-of-the-art accuracy of 70.70%, marking a 7% improvement over previous results.
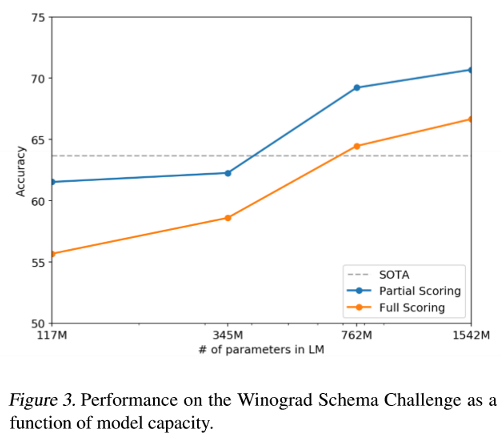
Diagram 4
OpenAI's summary of GPT-2's performance on various benchmark tests compared to the state of the art models at the time.
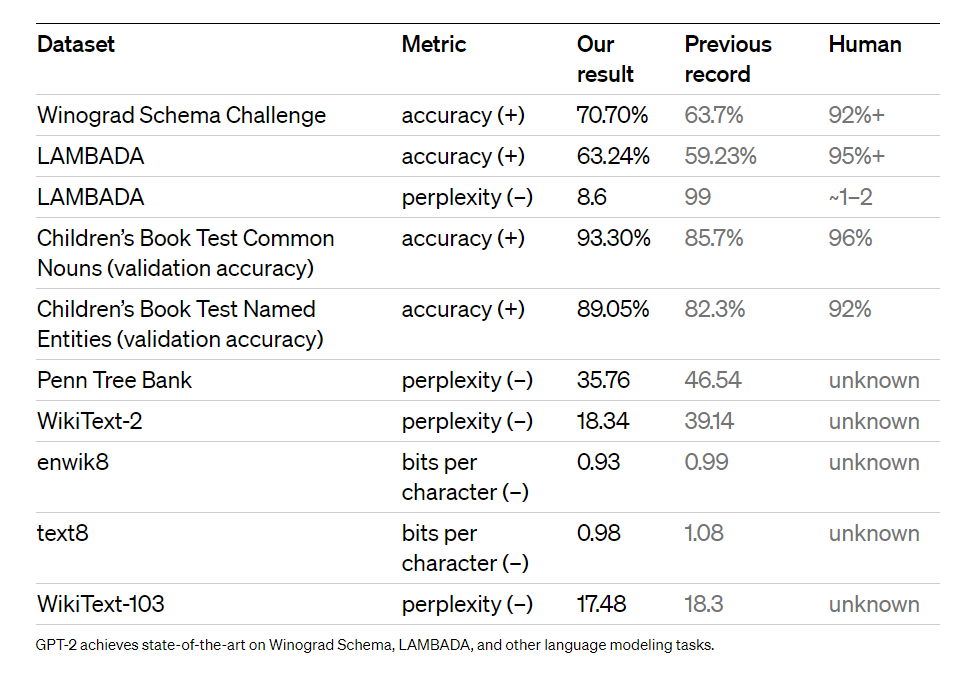
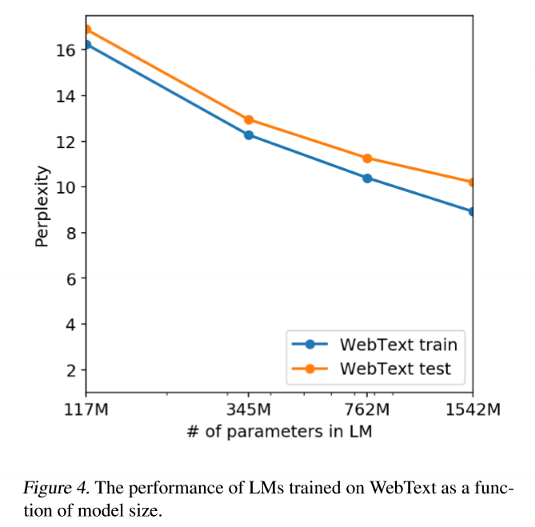
Diagram 5
The performance of GPT-2 model on both the training and test sets of WebText are similar and improve together as model size is increased suggesting that the model hasnt completely learned the patterns form the dataset and there is still potential to train bigger models and for longer.
References
[1] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Language Models are Unsupervised Multitask Learners
Team Members
Fatima Tourk and Shruti Biradar