Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
— By: Ayush Patel, Kush Suryavanshi, Spandan Maaheshwari
Analysis
The "Show, Attend and Tell" paper marks a pivotal advancement in image captioning by effectively integrating convolutional neural networks and recurrent neural networks with the novel introduction of attention mechanisms. This model surpasses traditional CNN-RNN approaches by allowing dynamic focus on different parts of an image during caption generation. The attention mechanism enables the network to produce more contextually relevant and accurate captions by mimicking human visual attention, which selectively focuses on various aspects of a scene for comprehension and description.
The empirical evidence presented in the paper highlights the model's superior performance in generating descriptive captions for images, demonstrating a more profound understanding of both visual elements and linguistic requirements. This is a significant leap in merging computer vision and natural language processing, showcasing the effectiveness of attention mechanisms in enhancing the quality and relevance of image captioning systems.
However, there are several areas where the model could be further improved. Enhancing the granularity of the attention mechanism could lead to more detailed captions, especially for complex scenes with multiple objects. Extending the model to handle video data through temporal attention, adapting it for different domains like medical imaging or satellite imagery, and enhancing multilingual and cultural adaptability are some areas that promise further advancements.
Finally, addressing interpretability and potential biases in the model's attention and captioning process is crucial for ethical AI development. Integrating this model with other natural language processing tasks such as question-answering or interactive storytelling could open new avenues for applications. These improvements and expansions could lead to more robust, versatile, and globally applicable systems in computer vision and natural language processing.
Literature Review
1. Foundation in Machine Translation ([Cho et.al., 2014]; [Bahdanau et al., 2014]; [Sutskever et al., 2014]):
In the realm of machine translation, researchers discovered that the interplay between convolutional neural networks (CNNs) and recurrent neural networks (RNNs) could be harnessed for the complex task of image captioning. These early explorations revealed that CNNs could adeptly extract nuanced visual features from images, which RNNs could then adeptly weave into coherent narratives. This foundational work set the stage for deep learning models to bridge the gap between visual perception and linguistic expression.
2. Early Neural Network Approaches:
Pioneering approaches, such as those by Kiros et al. (2014a) and Kiros et al. (2014b), introduced multimodal learning frameworks that integrated log-bilinear models influenced by image features, enhancing the correlation between visual data and language. Mao et al. (2014) further refined this approach by replacing traditional feed-forward language models with recurrent structures, thus improving the continuity and contextual relevance of generated captions. Vinyals et al. (2014) and Donahue et al. (2014) innovated by incorporating Long Short-Term Memory (LSTM) networks, with the novel approach of exposing the image to the LSTM only once at the start of the generation process, promoting a more focused and efficient captioning process.
3. Joint Embedding Space [Karpathy & Li 2014]:
The conceptualization of joint embedding space was a leap forward, allowing for a more integrated and symbiotic relationship between image and text. This space emerged as a pivotal learning environment for evaluating the complex interplay between visual inputs and their corresponding linguistic descriptions, carefully measuring how closely image content aligns with the text used to describe it. By leveraging object detection and sophisticated language processing, the models could discern and articulate the semantic synergy between seen images and spoken words with greater precision.
4. Object Detection-Based Approaches [Fang et al. (2014)]:
The integration of object detection methodologies into the caption generation pipeline marked a significant advancement, introducing a level of specificity and relevance previously unattained. This approach allowed for a precise identification of visual elements within images, providing a solid foundation upon which descriptive captions could be constructed. This method underscored the significance of granular visual understanding in the accurate and rich depiction of images through text.
5. Attention in Neural Networks [Tang et al., 2014)]:
The introduction of attention mechanisms by Larochelle & Hinton, Denil et al., and Tang et al. represented a monumental shift towards more dynamic and context-aware neural networks. Bahdanau et al.’s integration of attention into neural machine translation, followed by Ba et al.'s work on multiple object recognition with visual attention, provided the critical stepping stones for incorporating attention mechanisms into image captioning, culminating in the enhanced ability of models to selectively concentrate on salient features of an image to generate relevant and accurate captions.
Biography

1. Kelvin Xu: AI Researcher at Google Deepmind
Kelvin Xu is a leading figure in artificial intelligence, renowned for his work on practical AI systems. An alumnus of the University of California, Berkeley, and the MILA lab at Université de Montréal, he has studied under AI pioneers like Prof. Yoshua Bengio. With a foundation in deep learning, image captioning, and reinforcement learning from his tenure at Google's Brain Residency Program and the University of Toronto, Kelvin's expertise is pushing the boundaries of AI technology.

2. Jimmy L. Ba: AI Innovator and Educator
Serving as an Assistant Professor at the University of Toronto, Jimmy L. Ba is renowned for his significant contributions to AI, including co-developing the Adam Optimizer. His academic journey, mentored by AI luminaries like Geoffrey Hinton, spans from an undergraduate to a Ph.D. at the University of Toronto. Holding the Canada CIFAR AI Chair at the Vector Institute, his research delves into reinforcement learning and statistical learning theory. Honored with the Facebook Graduate Fellowship, Jimmy's notable achievement includes leading his team to victory at the CVPR 2015 caption generation competition. His work epitomizes the quest for creating AI that mirrors human ingenuity and adaptability.

3. Jamie Ryan Kiros: Eminent Machine Learning Researcher
Jamie Ryan Krios, a distinguished researcher who recently earned a Ph.D. from the Machine Learning Group at the Department of Computer Science, University of Toronto has established herself with seminal work like "Layer Normalization". Mentored by leading figures such as Dr. Ruslan Salakhutdinov and Dr. Richard Zemel, her research has garnered acclaim, reflected in the significant scholarly citations it has attracted. Jamie's dedication to advancing machine learning techniques and her collaboration with pioneers like Jimmy L. Ba and Geoffrey Hinton highlights her role as a key contributor to the field. Her trajectory promises continued innovation and influence in machine learning.

4. Kyunghyun Cho: AI Pioneer in Communication and Translation
Kyunghyun Cho, currently an Associate Professor of Computer Science and Data Science at NYU's Courant Institute of Mathematical Sciences, is a leading researcher in the field of artificial intelligence with a passion for building intelligent machines that actively engage in communication, knowledge-seeking, and knowledge creation. His groundbreaking work on attention mechanisms has advanced the field of neural machine translation, impacting both academia and industry. With accolades like the Google Research Award and influential publications, Cho is shaping the future of AI, fostering intelligent communication between machines for complex problem-solving.

5. Aaron Courville: Innovator in Machine Learning and AI
Dr. Aaron Courville, holding the Canada CIFAR AI Chair at Mila and a faculty position at Université de Montréal, is renowned for his expertise in deep learning and probabilistic models. His educational journey, rooted in Electrical Engineering from the University of Toronto and enriched by a PhD from Carnegie Mellon University, has led to his recognition as a leading expert in AI. His research ambitiously traverses computer vision, natural language processing, and audio signal comprehension. Collaborative efforts with luminaries like Yoshua Bengio and landmark papers such as "Show, Attend and Tell" highlight his influential role in shaping the field. Dr. Courville's commitment to innovation is further evidenced by his participation in winning teams for prestigious AI challenges, underscoring his significant impact on global AI advancements.

6. Ruslan Salakhutdinov: Architect of Modern Machine Learning
Dr. Ruslan Salakhutdinov, a leading voice in machine learning, has made significant strides in deep learning and optimization since earning his Ph.D. from the University of Toronto. His postdoctoral tenure at MIT's AI Lab paved the way for his influential role at Carnegie Mellon University. A recipient of numerous prestigious accolades such as the Alfred P. Sloan Research Fellowship and awards from Google and Nvidia, Ruslan's work delves into the complexities of vast datasets. His editorial contributions to the Journal of Machine Learning Research and service on program committees for conferences like NIPS and ICML speak to his dedication to the field. At the Canadian Institute for Advanced Research, he continues to be instrumental in evolving the landscape of machine learning, pushing the frontiers of AI towards new realms of possibility.

7. Richard S. Zemel: Luminary in Computer Science and AI Innovation
Professor Richard S. Zemel, renowned for his extensive work in computer science, holds a prestigious position at the University of Toronto. His diverse academic background includes a B.Sc. from Harvard and a Ph.D. under Geoffrey Hinton. Zemel's research has been pivotal in areas like unsupervised learning and machine learning for cognitive tasks. Not only an academic but also an entrepreneur, he co-founded SmartFinance. With honors like the NVIDIA Pioneers of AI Award, his influence extends to his leadership roles within the machine learning community, including on the Neural Information Processing Society's Executive Board.

8. Yoshua Bengio: Turing Award Laureate
Professor Yoshua Bengio, a Full Professor at Université de Montréal, is a vanguard in artificial intelligence, recognized globally for his profound contributions, particularly in deep learning. As Founder and Scientific Director of Mila and IVADO, his work has earned him the esteemed 2018 A.M. Turing Award, an accolade often equated with the Nobel Prize in computing. His accolades include fellowships with the Royal Societies of London and Canada, the Legion of Honor, and a CIFAR AI Chair. A guiding force in AI policy, Dr. Bengio also serves on the UN's Scientific Advisory Board, further cementing his role as a visionary in AI's evolution.
Model Architecture

CNN Encoder
- The model takes a single raw image and generates a caption y encoded as a sequence of 1-of-K encoded words, where K is the size of the vocabulary and C is the length of the caption.

- A convolutional neural network (CNN) is used to extract a set of feature vectors which we refer to as annotation vectors.
- The extractor produces L vectors, each of which is a D-dimensional representation corresponding to a part of the image.

Features are extracted from a lower convolutional layer. This allows the decoder to selectively focus on certain parts of an image by weighting a subset of all the feature vectors.
- e.g.: the 14×14×512 feature map of the fourth convolutional layer before max pooling in ImageNet-Pretrained VGGNet is used.
- The decoder operates on the flattened 196×512 (i.e. L×D) encoding.
Attention Decoder
2.1. Attention Decoder
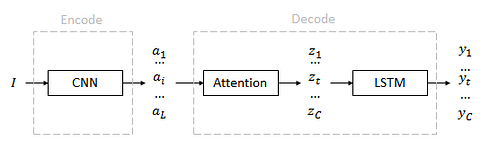
- A long short-term memory (LSTM) network is used that produces a caption by generating one word at every time step conditioned on a context vector, the previous hidden state and the previously generated words.
- The context vector is a dynamic representation of the relevant part of the image input at time t.
- A mechanism that computes from the annotation vectors , i=1, …, L corresponding to the features extracted at different image locations.
For each location i, the mechanism generates a positive weight i which can be interpreted either as the probability that location i is the right place to focus for producing the next word (stochastic attention mechanism), or as the relative importance to give to location i in blending the ’s together (deterministic attention mechanism).
- The weight i of each annotation vector is computed by an attention model for which a multilayer perceptron is used which is conditioned on the previous hidden state .
- To emphasize, the hidden state varies as the output RNN advances in its output sequence: “where” the network looks next depends on the sequence of words that have already been generated.

- Once the weights (which sum to one) are computed, i.e. softmax, the context vector is computed by:

- Here, is a function that returns a single vector given the set of annotation vectors and their corresponding weights. This function is mentioned in the next sub-section.

2.2. Stochastic “Hard” Attention & Deterministic “Soft” Attention
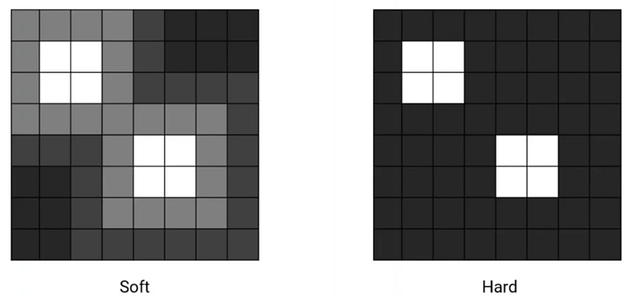
- The hard attention focuses only on the part it wants and ignores other parts while the soft attention is smooth.
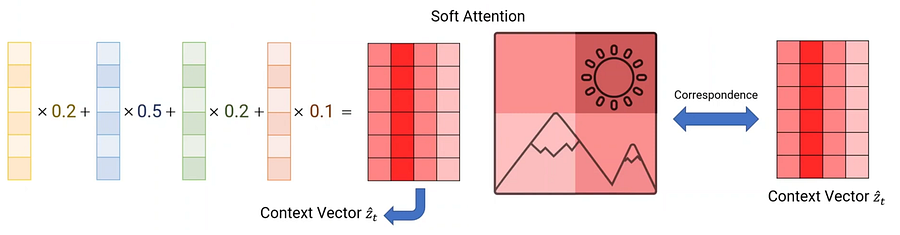
- In soft attention, different weights based on the image are used.
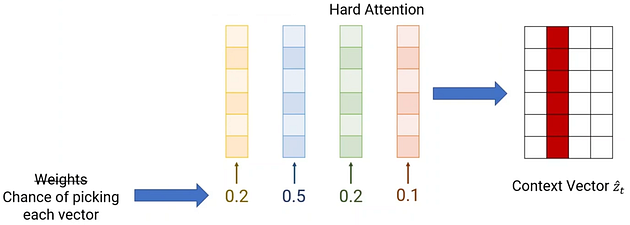
- In hard attention, only the most important part is used.

Experimental Results

- Each image in the Flickr8k/30k dataset has 5 reference captions.
- For the MS COCO dataset, captions in excess of 5 are discarded.
- A fixed vocabulary size of 10,000 is used.
Show, Attend & Tell obtains the SOTA performance on the Flickr8k, Flickr30k and MS COCO, e.g. outperforms Show and Tell/NIC.

- The model learns alignments that agree very strongly with human intuition.

- However, the proposed model also makes mistakes, which means there is room for improvement.
Implementation Results
Below are the implementation results performed by our model which uses Bahdanau’s Soft attention mechanism on the MS COCO dataset. The images along with the caption on the left are of Inception V3 and those on the right are of VGG-19. A fixed vocabulary size of 5,000 is used. We have trained the model using 30,000 images and captions and tested on 10,000 images and captions.
Original Image



Original Image



Original Image



Original Image



| BLUE-1 | BLUE-2 | BLUE-3 | BLUE-4 | METEOR | |
|---|---|---|---|---|---|
| Paper | 70.7 | 49.2 | 34.4 | 24.3 | 23.9 |
| Inception V3 | 36.00 | 12.42 | 6.20 | 3.17 | 10.04 |
Results from our implementation vs the results from the best model implemented by the author
Social Impact
The advancements presented in the paper bear a significant potential to transform various sectors of society. The introduction of an attention-based model enhances the precision and relevance of image captions, which is a substantial boon for assistive technologies. Such a system could revolutionize the way people with visual impairments interact with digital content, offering them a newfound level of independence in navigating online spaces and understanding visual media.
In the educational domain, the application of sophisticated image captioning can facilitate more immersive learning experiences, especially for visual learners and students who rely on augmented communication aids. It also has the potential to augment cultural experiences, such as providing dynamic descriptions of artworks or historical artifacts in museums, thus bridging the gap between visual content and its historical or cultural context.
On the industrial front, the attention-based model can be pivotal in enhancing the efficiency of visual quality control systems in manufacturing, where the ability to accurately describe anomalies could lead to significant improvements in product quality. In the realm of media, such technology could automate the generation of alt-text for images, streamlining content creation and making it more inclusive.
However, as we leverage these models, there is a risk of encoding and perpetuating existing societal biases. The model’s interpretative capabilities are as good as the data it is fed. Hence, if the underlying datasets are skewed or discriminatory, the captions generated could inadvertently perpetuate stereotypes or misrepresentations. Furthermore, in the context of surveillance, the technology could be utilized in ways that infringe upon personal privacy and civil liberties if safeguards are not put in place.
The ethical deployment of these models necessitates rigorous scrutiny of training datasets and transparent disclosure of the technology's use cases. Policymakers and technologists must work in tandem to establish guidelines that safeguard privacy while promoting the beneficial uses of image captioning technologies, ensuring that their societal impact is aligned with principles of equity and justice.
Industry Applications
The paper presents a method that holds promising practical applications. It has applications in areas where data is multi-modal such as e-commerce, where data contains text in the form of metadata as well as images, or in healthcare, where data could contain MRIs or CT scans along with doctor’s notes and diagnoses, to name a few use cases.
- E-commerce – E-commerce in particular stores vast amounts of data as product images along with textual descriptions. The textual description or metadata is important to ensure that the best products are displayed to the user based on the search queries. Moreover, with the trend of e-commerce sites obtaining data from 3P vendors, the product descriptions are often incomplete, amounting to numerous manual hours and huge overhead resulting from tagging the right information in the metadata columns. Generative-AI-based image captioning is particularly useful for automating this laborious process. Fine-tuning the model on custom fashion data such as fashion images along with text describing the attributes of fashion products can be used to generate metadata that then improves a user’s search experience.
- Media and Publishing: Image captioning can be used in media and publishing industries to automatically generate captions for images in news articles, blogs, or social media posts. This helps provide context and enhances the engagement of readers by providing relevant information about the visual content.
- Healthcare: Image captioning can assist medical professionals in the analysis and interpretation of medical images, such as X-rays, MRI scans, or histopathology slides. Automatically generated captions can provide additional insights and help in accurate diagnosis and treatment planning.
- Content Management: Image captioning can be used in content management systems to automatically generate captions for images uploaded by users. This simplifies the process of organizing and searching for images within a large database, making it easier to retrieve specific images based on their content.
- Education: Image captioning can be utilized in educational settings to provide visual descriptions for educational materials, such as textbooks, presentations, or online courses. This benefits students with visual impairments or those who prefer learning through text-based information.
- Social Media: Image captioning can be valuable in the social media industry, where users share a large number of images. Automatically generating captions for these images can improve accessibility, searchability, and engagement on social media platforms.
These are just a few examples of the many industry applications of image captioning. The technology has the potential to streamline processes, improve accessibility, and enhance user experiences across various domains.
Follow on Research
2015-2016: Early Improvements and Transformer Introduction
- Researchers began improving upon the LSTM-based models by addressing their limitations in handling long-term dependencies.
- The introduction of transformer architecture by Vaswani et al. in 2017 began to influence image captioning approaches, although widespread adoption in this field would take a couple more years.
2017-2018: Rise of Transformer Models and Object Relation Focus
- Following the success of transformers in NLP, attention began to shift towards applying these models to image captioning, focusing on the global context within images.
- Studies on object relation models started to gain traction, aiming to capture interactions between objects in an image for richer captions.
2019: Multi-Modal Pre-trained Transformers
- OpenAI introduced models like CLIP and later DALL-E, which could learn from both text and images, enabling more advanced captioning and content generation capabilities.
2020: Audio-Visual Models and Cross-Lingual Capabilities
- There was an increased emphasis on audio-visual models, integrating sound and image data for comprehensive sensory descriptions.
- Research on cross-lingual captioning expanded, allowing models to generate captions in various languages and broadening the accessibility of the technology.
2021: Dataset Diversification and Bias Mitigation
- The AI community focused on curating more diverse datasets to reduce bias in image captioning models.
- Concurrently, algorithms began to be developed for detecting and correcting biases in generated captions.
2022: Interpretability and Real-time Captioning
- The push for interpretability in AI saw the development of models that could provide insight into their captioning decisions.
- Advances in real-time captioning and edge computing emerged, aiming to make image captioning more efficient and applicable in low-resource environments.
2023 and Beyond: Ongoing and Future Directions
- The ethical use of image captioning technology, especially concerning privacy and surveillance, continues to be a critical area of discussion.
- Domain-specific applications, particularly in healthcare, are seeing tailored image captioning models that assist in diagnostic processes.
Peer Review
Summary:
The paper introduces two innovative attention-based image captioning models: a "soft" deterministic approach and a "hard" stochastic variant. Distinctively, it diverges from prior methods by leveraging an attention mechanism to selectively focus on relevant image segments during caption generation, instead of compressing the entire image into a single vector. This nuanced approach has led to exceptional performance across standard datasets like Flickr8k, Flickr30k, and MS COCO, marking a significant stride in the field.
Strengths and Weaknesses
- Originality:
- The paper's introduction of visual attention in caption generation is a pioneering approach. Its integration with encoder-decoder RNNs demonstrates ingenuity and a deep understanding of the field's needs.
- The literature review comprehensively acknowledges related works, ensuring the model's novelty is contextualized within the existing body of research.
- Quality:
- Methodologically, the paper stands on a solid foundation, with its experimental design adhering to rigorous standards. The models are evaluated against well-established benchmarks, showcasing their superiority in performance.
- The depth of evaluation, covering multiple datasets, reinforces the robustness of the proposed methods.
- Clarity:
- The paper excels in presenting complex ideas with clarity. The attention mechanism and its integration into the model are elucidated with precision, making the paper accessible to both experts and those new to the field.
- The use of visual aids in explaining the model’s workings significantly enhances the reader's understanding.
- Significance:
- This work represents a significant leap in the field of image captioning, especially in terms of interpretability and alignment with human perception.
- The practical implications of this research are vast, potentially impacting numerous applications from assistive technologies to content creation.
- Weaknesses:
- The paper, while technically sound, lacks a discussion on the societal implications of the technology, especially regarding privacy and ethical use.
- There is also a missed opportunity in not exploring the limitations or potential biases inherent in the training data, which could impact the model's performance in real-world scenarios.
Confidence Score: 8 - Strong Accept
- The paper's technical proficiency is evident in the attention mechanism it introduces, setting it apart from previous state-of-the-art methods.
- The thoroughness in evaluation, demonstrated across multiple datasets, underscores the model's effectiveness and reliability.
- The clarity and structure of the paper, combined with insightful visualizations, contribute significantly to its academic merit.
- Despite the lack of discussion on broader societal impacts, the paper's technical contributions and the potential for practical application make it a valuable addition to the field.
In conclusion, the paper is a noteworthy contribution to image captioning, offering innovative approaches and setting new performance benchmarks. Its strengths in originality, quality, clarity, and significance make it a strong candidate for acceptance, with the potential to influence future research and applications in the field.
References
[Cho et.al., 2014] Cho, Kyunghyun, van Merrienboer, Bart, Gulcehre, Caglar, Bougares, Fethi, Schwenk, Holger, and Bengio, Yoshua. Learning phrase representations using RNN encoder-decoder for statistical machine translation In EMNLP, October 2014.
[Bahdanau et al., 2014] Bahdanau, Dzmitry, Cho, Kyunghyun, and Bengio, Yoshua. Neural machine translation by jointly learning to align and translate CoRR 2014.
[Sutskever et al., 2014 ] Sutskever, Ilya, Vinyals, Oriol, and Le, Quoc VV. Sequence to sequence learning with neural networks. NIPS2014.
[Donahue et al. 2014 ] Donahue, Jeff, Hendrikcs, Lisa Anne, Guadarrama, Segio,Rohrbach, Marcus, Venugopalan, Subhashini, Saenko, Kate, and Darrell, Trevor. Long-term recurrent convolutional networks for visual recognition and description. arXiv:1411.4389v2, November 2014.
[Kiros et al. 2014a ] Kiros, Ryan, Salahutdinov, Ruslan, and Zemel, Richard. Multimodal neural language models. In International Conference on Machine Learning, pp. 595–603, 2014a.
[Kiros et al. 2014b ] Kiros, Ryan, Salahutdinov, Ruslan, and Zemel, Richard. Unifying visual-semantic embeddings with multimodal neural language models. arXiv:1411.2539, November 2014b.
[Mao et al. 2014 ] Mao, Junhua, Xu, Wei, Yang, Yi, Wang, Jiang, and Yuille, Alan. Deep captioning with multimodal recurrent neural networks (m-run). arXiv:1412.6632, December 2014.
[Vinyals et al. 2014 ] Vinyals, Oriol, Toshev, Alexander, Bengio, Samy, and Erhan, Dumitru. Show and tell: A neural image caption generator. arXiv:1411.4555, November 2014.
[Karpathy & Li 2014] Karpathy, Andrej and Li, Fei-Fei. Deep visual-semantic alignments for generating image descriptions. arXiv:1412.2306, December 2014.
[Fang et al. (2014)] Fang, Hao, Gupta, Saurabh, Iandola, Forrest, Srivastava, Rupesh, Deng, Li, Doll´ar, Piotr, Gao, Jianfeng, He, Xiaodong, Mitchell, Margaret, Platt, John, et al From captions to visual concepts and back. arXiv:1411.4952, November 2014.
[Larochelle & Hinton (2010)] Larochelle, Hugo and Hinton, Geoffrey E. Learning to combine foveal glimpses with a third-order Boltzmann machine. In NIPS, pp. 1243–1251, 2010.
[ Denil et al. (2012)] Denil, Misha, Bazzani, Loris, Larochelle, Hugo, and de Freitas, Nando. Learning where to attend with deep architectures for image tracking. Neural Computation, 2012.
[Tang et al. (2014)] Tang, Yichuan, Srivastava, Nitish, and Salakhutdinov, Ruslan R. Learning generative models with visual attention. In NIPS, pp.1808–1816, 2014.
[Mnih et al. (2014)] Mnih, Volodymyr, Hees, Nicolas, Graves, Alex, and Kavukcuoglu, Koray. Recurrent models of visual attention. In NIPS, 2014.
[Ba et al. (2014)] Ba, Jimmy Lei, Mnih, Volodymyr, and Kavukcuoglu, Koray. Multiple object recognition with visual attention. arXiv:1412.7755, December 2014.