Introduction
As AI systems, especially large language models (LLMs), become deeply embedded in critical applications, the need to interpret and control their behavior has become increasingly urgent. Yet, these models are often described as "black boxes" due to their opaque decision making processes, which makes it difficult to understand, debug, or adjust specific behaviors. This lack of transparency creates challenges in bias mitigation, error correction, and ensuring ethical alignment.
Mechanistic interpretability is an emerging subfield of AI that seeks to uncover how these models work internally. It asks essential questions: What drives their predictions? Why do they hallucinate? How can we better control them? Among the newest tools in this space are Sparse Autoencoders (SAEs), which help break down and interpret a model's internal representations into human-understandable features.
In this project, I employ SAEs to make the Gemma 2 2B language model "forget" knowledge about the Harry Potter universe. This concept, known as machine unlearning, is the ability to selectively remove specific concepts or data from a model. This capability is especially important in light of growing privacy concerns and legal requirements like the EU’s data regulations.
Unlearning methods generally fall into two categories: Exact Unlearning, which requires complete retraining—computationally expensive and often impractical; and Approximate Unlearning, which uses techniques like parameter-efficient fine-tuning (PEFT) but often results in catastrophic forgetting or other unintended side effects. Additionally, these approaches lack interpretability.
SAE-based unlearning offers a promising alternative. It not only avoids full retraining but also provides a transparent explanation of which internal features correspond to which input concepts. By ablating (i.e., suppressing) the activations of features associated with unwanted knowledge, we can simulate the effect of the model having never learned that data in the first place.
The central question driving this work is:
Can we effectively and interpretably unlearn specific concepts in a language model using Sparse Autoencoders, while preserving the model’s overall performance?
Related Work
The concept of machine unlearning has garnered significant attention due to its implications for privacy and model adaptability. Cao and Yang (2019) introduced one of the earliest formalizations of unlearning, proposing methods to efficiently remove data points from models without retraining from scratch. However, their approach primarily focused on structured data and lacked the interpretability needed for understanding which specific concepts were being unlearned.
More recent work by Eldan and Russonovich (2023) explored unlearning in the context of language models, particularly focusing on fictional characters like Harry Potter. Their study demonstrated that traditional unlearning techniques, such as fine-tuning on "forget" datasets, often lead to unintended side effects, including the degradation of unrelated knowledge. This highlights the need for more precise, interpretable methods like SAE-based unlearning.
Lieberum et al. (2024) introduced Gemma Scope, a comprehensive suite of SAEs trained on the Gemma 2 models. Their work provides a foundational toolset for interpreting and manipulating internal model representations, enabling targeted interventions like unlearning specific concepts.
Autoencoders
Autoencoders are unsupervised neural networks designed to learn compact, efficient representations of data. They consist of three core components:
- Encoder: Transforms the input \( x \) into a compressed latent representation \( h \) via \( h = f(x) \).
- Bottleneck (Latent Space): The reduced dimensionality \( h \) retains the input’s critical features.
- Decoder: Reconstructs the input as \( \tilde{x} \) from \( h \) using \( \tilde{x} = g(h) \).
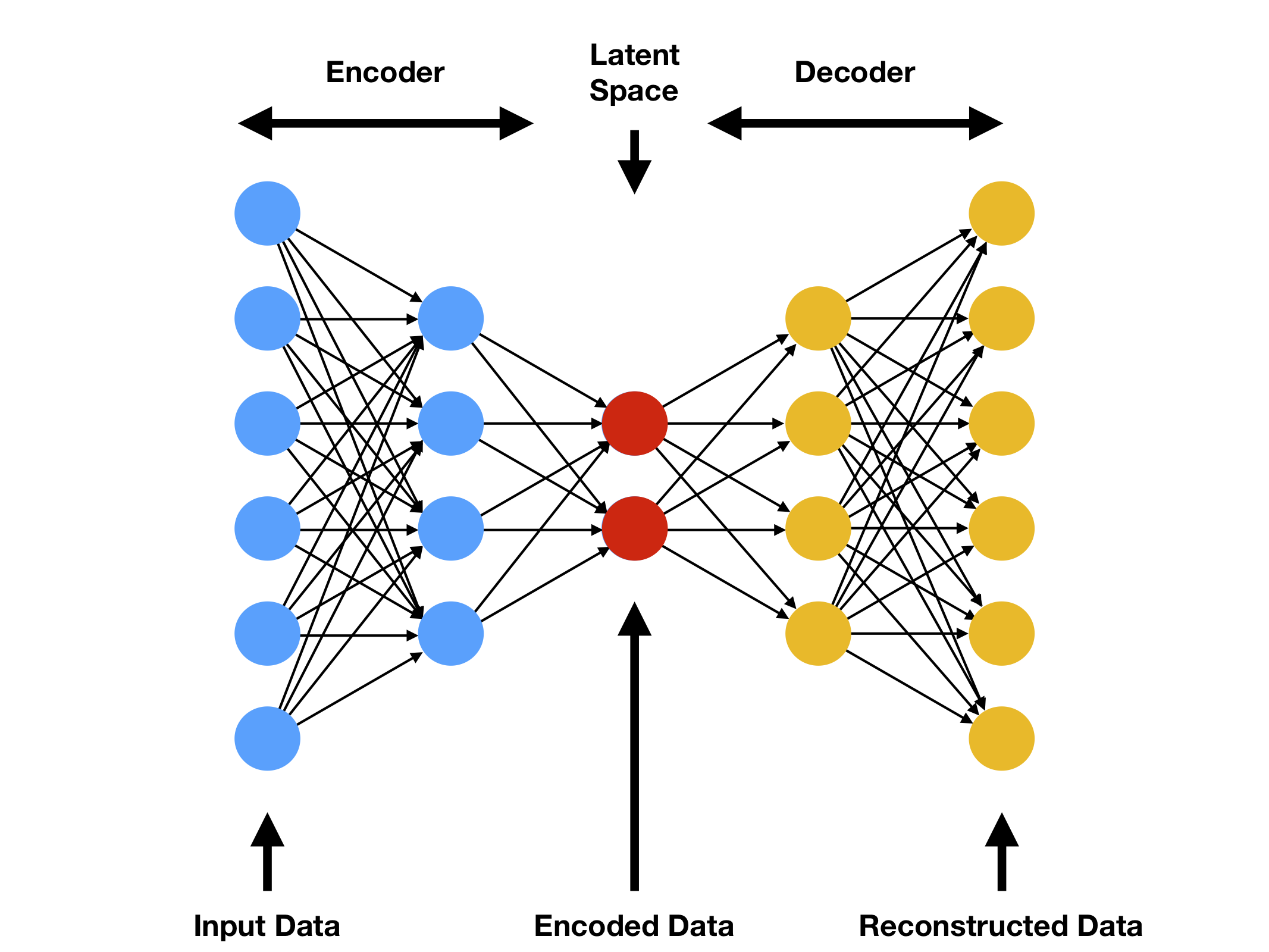
Image source: Compthree Blog
The training objective is to minimize the reconstruction loss, typically the mean squared error: \( L = \lVert x - \tilde{x} \rVert_2^2 \), allowing the autoencoder to distill meaningful patterns into the latent space.
Sparse Autoencoders
Sparse Autoencoders (SAEs) are a specialized variant of autoencoders that enforce sparsity in the latent representation \( h \). In SAEs, the latent dimension \( M \) is significantly larger than the input dimension \( x \) (\( M \gg x \)), but only a small fraction of the latent units are active (non-zero) for any given input. This sparsity ensures that the most important information is captured by a smaller set of active latents, enhancing interpretability.
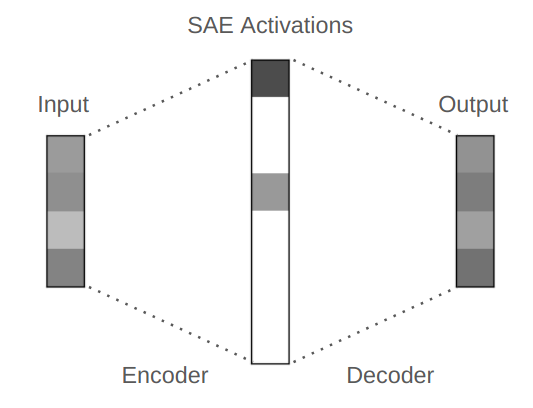
Image source: Adam Karvonen
Why Sparsity?
- Interpretability: Sparse representations isolate distinct features, making them easier to understand and analyze.
- Efficiency: Fewer active units reduce computational overhead during analysis and manipulation.
Mechanism: Given activations \( \mathbf{x} \in \mathbb{R}^n \) from a language model, an SAE decomposes and reconstructs them using encoder and decoder functions:
- Encoder: \( \mathbf{f}(\mathbf{x}) = \sigma(\mathbf{W}_{\text{enc}} \mathbf{x} + \mathbf{b}_{\text{enc}}) \)
- Decoder: \( \hat{\mathbf{x}}(\mathbf{f}) = \mathbf{W}_{\text{dec}} \mathbf{f} + \mathbf{b}_{\text{dec}} \)
Here, \( \sigma \) is the activation function, and \( \mathbf{f}(\mathbf{x}) \in \mathbb{R}^M \) specifies how to combine the \( M \) columns of \( \mathbf{W}_{\text{dec}} \) (the dictionary of learned directions, or latents) to reconstruct \( \mathbf{x} \). Sparsity is enforced through the choice of \( \sigma \) and regularization techniques.
Gemma Scope

Image credits: Gemma Scope
Gemma Scope is a comprehensive suite of over 400 JumpReLU Sparse Autoencoders (SAEs) trained on every layer and sub-layer of the Gemma 2 language models (2B, 9B, and select layers of 27B parameters), developed by Google DeepMind.
Scale and Resources:
- Contains over 30 million learned features, trained on 4–16 billion tokens each.
- Used over 20% of GPT-3’s training compute and saved ~20 Pebibytes of activations.
- Produced hundreds of billions of parameters, covering attention, MLP, and residual stream locations per layer .
Training Process:
- Data: SAEs are trained on activations from text data matching Gemma 1’s pretraining distribution, excluding BOS, EOS, and padding tokens.
- Locations: SAEs are trained at three sites per layer: attention head outputs (before final linear transformation and RMSNorm), MLP outputs (after RMSNorm), and post-MLP residual stream .
- Hyperparameters: Uses a learning rate of \( 7 \times 10^{-5} \), cosine warmup over 1,000 steps, Adam optimizer with \((\beta_1, \beta_2) = (0, 0.999)\), and a sparsity coefficient warmup over 10,000 steps. The JumpReLU threshold is initialized at 0.001, and decoder weights are normalized to unit norm after each update .
- Infrastructure: Trained on TPUv3 (4x2 configuration) and TPUv5p (2x2x1 or 2x2x4), with optimized sharding (data parallelism for small SAEs, tensor parallelism for larger ones) and a shared server system for high-throughput disk reads (>1 GiB/s). Activations are stored as 32-bit precision raw bytes in 10-20 GiB shards, totaling ~17 PiB for Gemma 2 2B and 9B .
- Suite Details: SAEs range from 16.4K to 1M latents, with training durations of 4B tokens for 16.4K-width SAEs, 8B for most, and 16B for 1M-width SAEs .
Loss Function: SAEs are trained with a loss function balancing reconstruction accuracy and sparsity:
\[ \mathcal{L} = \lVert \mathbf{x} - \hat{\mathbf{x}}(\mathbf{f}(\mathbf{x})) \rVert_2^2 + \lambda \lVert \mathbf{f}(\mathbf{x}) \rVert_0 \]Here, \( \lambda \) is the sparsity penalty coefficient, and \( \lVert \mathbf{f}(\mathbf{x}) \rVert_0 \) counts non-zero latents. The piecewise constant nature of JumpReLU and \( L_0 \) penalty requires straight-through estimators (STEs) to train \( \boldsymbol{\theta} \), using a kernel density estimator bandwidth \( \varepsilon = 0.001 \) for stable gradients .
Applications and Evaluation Insights:
- Applications: Gemma Scope's SAEs can be used for detecting and fixing hallucinations, circuit analysis, and machine unlearning by suppressing specific features .
- Evaluation Insights: Residual stream SAEs show higher delta LM loss than MLP or attention SAEs, likely due to their role as a bottleneck for inter-layer communication. Reconstruction loss varies by sequence position, and SAEs perform best on formulaic data (e.g., mathematics) and worst on multilingual data (e.g., Europarl) .
JumpReLU Activation Function
The JumpReLU activation function, employed in Gemma Scope’s Sparse Autoencoders, combines a shifted Heaviside step function with a ReLU, defined as:
\[ \sigma(\mathbf{z}) = \text{JumpReLU}_{\boldsymbol{\theta}}(\mathbf{z}) = \mathbf{z} \odot H(\mathbf{z} - \boldsymbol{\theta}) \]Here, \( \boldsymbol{\theta} > 0 \) is a learnable threshold vector unique to each latent, \( \odot \) denotes element-wise multiplication, and \( H \) is the Heaviside step function (1 if input > 0, 0 otherwise). Unlike the standard ReLU, which activates all positive inputs with a fixed threshold of zero, JumpReLU only activates inputs exceeding the learnable threshold \( \boldsymbol{\theta} \), enhancing sparsity control. While ReLU’s threshold is static, \( \boldsymbol{\theta} \) in JumpReLU is optimized during training using straight-through estimators (STEs) to handle the non-differentiable Heaviside function, with a kernel density estimator bandwidth \( \varepsilon = 0.001 \) ensuring stable gradients. This adaptability allows JumpReLU to tailor activation thresholds to the data, improving feature sparsity and interpretability over ReLU’s fixed approach.
In summary, JumpReLU’s learnable threshold and STE optimization enable it to achieve a balance between sparsity and reconstruction accuracy, making it a powerful tool for feature extraction in SAEs.
My Experiments: Unlearning Harry Potter Concepts
This project leverages Gemma Scope’s Sparse Autoencoders (SAEs) to selectively remove Harry Potter-related knowledge from the Gemma 2 2B language model. The experiment targets three layers—0, 12, and 25—representing early, middle, and late stages of the model’s processing pipeline. The goal is to disrupt specific conceptual understanding (e.g., Hogwarts, Quidditch) while preserving the model’s general language capabilities. The methodology is structured into the phases: feature identification, feature ablation, and evaluation.
Methodology
- Feature Identification:
- Tool: Neuronpedia, an open-source platform for analyzing SAE latents, is used to correlate latent activations with semantic concepts.
- Selection: A set of Harry Potter-related keywords (e.g., “Who is Harry Potter?”, “Describe a Quidditch match at
Hogwarts”) is fed into the model. Neuronpedia identifies latents with high activation for these prompts,
indicating their association with Harry Potter concepts. The top features are selected based on activation strength.
- Layer 0: 439 features, capturing broad, low-level patterns.
- Layer 12: 180 features, representing mid-level, concept-specific representations.
- Layer 25: 200 features, encoding high-level, abstract concepts.
- A few explanations of the features being ablated from Layer 0:
- Feature 14344 corresponds to references to various sports tournaments ( could be trigerred by Quidditch)
- Feature 14966 corresponds references to faculty members and academic staff ( could be trigerred by Dumbeldore)
- Feature 12865 corresponds references to the concept of "mirror" in various contexts ( could be trigerred by the Mirror of Erised )
- Feature Ablation:
- Implementation: A custom PyTorch forward hook is designed to suppress Harry Potter-related features during inference:
- Encoding: The residual stream activation \( \mathbf{x} \) at the specified layer is encoded into the SAE’s latent space \( \mathbf{f}(\mathbf{x}) \) using the SAE’s encoder.
- Ablation: The identified Harry Potter-related latents (e.g., 439 for layer 0) are set to zero in \( \mathbf{f}(\mathbf{x}) \), effectively neutralizing their contribution.
- Decoding: The modified latent vector is decoded back to a reconstructed activation \( \hat{\mathbf{x}} \), which replaces the original \( \mathbf{x} \) in the model’s forward pass.
- Application: The hook is applied at the designated hook point
(
blocks.{layer}.hook_resid_pre) for each layer during inference. Separate hooks are used for layers 0, 12, and 25.
- Implementation: A custom PyTorch forward hook is designed to suppress Harry Potter-related features during inference:
- Evaluation:
- Datasets: Three datasets, each limited to 1,000 samples for computational efficiency, are used to assess the impact of ablation:
- Original WikiText-2: A general text corpus containing occasional Harry Potter references, representing a baseline for general language performance.
- Cleaned WikiText-2: A filtered version of WikiText-2 with Harry Potter references removed, used to evaluate performance on unrelated text.
- Harry Potter Book 1: Excerpts from J.K. Rowling’s Harry Potter and the Philosopher's Stone, rich in target concepts, used to measure unlearning effectiveness.
- Metrics:
- Perplexity: Quantifies model uncertainty as \( \text{Perplexity} = \exp\left(\frac{1}{N} \sum -\log P(x_i)\right) \), where lower values indicate better performance. Perplexity is computed with and without ablation.
- Text Generation: The model generates 50 new tokens for a set of prompts at a temperature of 0.1 (for deterministic outputs). Prompts include:
- Harry Potter related: “Who is Harry Potter?”, “Tell me about Harry Potter’s adventures at Hogwarts”, “What is the significance of the Sorting Hat in Hogwarts?”, “Describe a Quidditch match at Hogwarts”.
- Unrelated: “Explain the history of the Roman Empire”, “What are the benefits of a healthy diet?”, “Describe a typical day in a modern city”.
- Datasets: Three datasets, each limited to 1,000 samples for computational efficiency, are used to assess the impact of ablation:
Experimental Setup
- Model: Gemma 2 2B, a transformer based language model, accessed via TransformerLens.
- SAEs: Gemma Scope’s 16K-width JumpReLU SAEs for layers 0, 12, and 25, trained on 4–16 billion tokens.
- Hardware: Google Colab with an A100 GPU.
- Libraries: PyTorch, TransformerLens, Neuronpedia, and tqdm (for progress bars).
Results and Analysis
The experiments evaluate the effectiveness of SAE-based unlearning by measuring perplexity and analyzing text generation quality across the three datasets and four conditions (no ablation, layer 0 ablation, layer 12 ablation, and layer 25 ablation). The results provide insights into the trade-offs between targeted unlearning and general model performance.
Perplexity Results
Perplexity measures the model’s uncertainty on the test datasets, with higher values indicating poorer performance. The table below summarizes perplexity results for each layer and dataset, including baseline perplexities (no ablation) sourced from typical Gemma 2 2B performance.
| Layer | WikiText-2 | Cleaned WikiText-2 | Harry Potter Book 1 |
|---|---|---|---|
| No Ablation | 17.93 | 18.37 | 26.94 |
| Layer 0 | 283.47 | 284.02 | 243.55 |
| Layer 12 | 52.98 | 54.14 | 137.55 |
| Layer 25 | 38.50 | 39.19 | 46.45 |
- No Ablation: Baseline perplexities are low , indicating strong model performance.
- Layer 0 (439 features ablated): Perplexity skyrockets to ~283–284 on general text and 243.55 on Harry Potter data, indicating catastrophic disruption of language processing due to the ablation of foundational features.
- Layer 12 (180 features ablated): Perplexity rises significantly to 137.55 on Harry Potter data, while remaining moderate (52–54) on general text, suggesting effective targeted unlearning with minimal collateral damage.
- Layer 25 (200 features ablated): Perplexity increases modestly (38–46) as compared to the baseline, indicating limited impact on Harry Potter knowledge and strong preservation of general performance.
Text Generation Results
Text generation provides qualitative insights into the model’s behavior under ablation, revealing how unlearning affects coherence and relevance.
Harry Potter-Related Prompts
- Prompt: “Who is Harry Potter?”
- No Ablation: “Harry Potter is a fictional character created by J.K. Rowling. He is the main protagonist of the Harry Potter series. He is a wizard and the only child of James and Lily Potter.”
- Layer 0: “<\strong>><\em>…<\em><\strong><\h2>” (repeated HTML tags), indicating severe incoherence.
- Layer 12: “Harry Potter is a fictional character in a series of novels by a British author, a serial of novels by a British author…,” showing repetition and loss of detail.
- Layer 25: “The only way to know is to read the books. Harry Potter and the Philosopher's…,” retaining structure but lacking specificity.
Unrelated Prompts
- Prompt: “What are the benefits of a healthy diet?”
- No Ablation: “A healthy diet is one that provides the body with the nutrients it needs to function properly. A healthy diet can help to prevent disease, improve energy levels, and promote weight loss.”
- Layer 0: “What is the benefits of a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a,” incoherent.
- Layer 12: “A healthy diet is one that is rich in nutrients and low in fat. A healthy diet is one that is rich in nutrients and low in fat…,” repetitive but correct.
- Layer 25: “A. It is a good way to lose weight. B. It is a good way to stay in shape. C. It is a good way to stay healthy…,” structured but slightly off-format.
Analysis
- Layer 0: Ablating 439 features causes a catastrophic collapse (perplexities >240, incoherent text), as early layers encode foundational features critical to syntax and semantics. This also indicates that in layer 0 there are features which overlap for the unleanr target and the unrelated prompts. This disrupts both Harry Potter and general knowledge, indicating feature entanglement.
- Layer 12: Ablating 180 features effectively unlearns Harry Potter knowledge (perplexity 137.55, degraded generation) while preserving general competence (perplexity 52–54, coherent unrelated responses). Mid-layers encode concept-specific representations, making layer 12 optimal for targeted unlearning.
- Layer 25: Ablating 200 features has limited impact (perplexity 38–46, partially degraded Harry Potter responses), as late layers encode abstract features less tied to specific concepts, preserving general performance.
The results highlight a trade-off: early-layer ablation is overly destructive, late-layer ablation is insufficiently targeted, and mid-layer ablation (layer 12) strikes an optimal balance. Feature entanglement in early layers remains a challenge, necessitating precise feature selection.
Discussion
This study demonstrates the potential of Sparse Autoencoders for interpretable machine unlearning, with layer 12 ablation emerging as the most effective approach for removing Harry Potter-related knowledge from the Gemma 2 2B model. The methodology—leveraging Gemma Scope’s SAEs, Neuronpedia for feature identification, and custom ablation hooks—offers a modular, scalable alternative to traditional unlearning techniques like retraining or fine-tuning. Unlike exact unlearning, which is computationally prohibitive, or approximate unlearning, which risks catastrophic forgetting, SAE-based unlearning avoids retraining and provides transparency into which features are targeted.
Key Findings
- Effectiveness of Unlearning: Layer 12 ablation significantly disrupts Harry Potter knowledge while maintaining general language competence, validating SAEs as a precise tool for concept-specific unlearning.
- Layer-Specific Effects: Early layers (0) are prone to catastrophic disruption, mid-layers (12) are ideal for targeted interventions, and late layers (25) preserve overall performance but are less effective for specific unlearning.
- Interpretability: Neuronpedia’s feature analysis enhances transparency, enabling clear identification of Harry Potter-related latents.
- Trade-Offs: Feature entanglement in early layers causes collateral damage, necessitating careful feature selection.
Implications
- Ethical AI: SAE-based unlearning addresses privacy and compliance needs by enabling selective data removal.
- Scalability: The modularity of SAE hooks reduces computational costs compared to retraining.
- Interpretability: Mapping latents to semantic concepts supports debugging and ethical alignment.
Limitations and Challenges
- Feature Entanglement: Early-layer features overlap, causing widespread disruption when ablated.
- Evaluation Scope: Limited to 1,000 samples and few prompts, potentially missing broader impacts.
- Generalization: Focused on one concept and model, requiring validation on other domains and models.
Future Directions
- Automated Feature Pruning: Develop algorithms to identify concept-specific latents automatically.
- Multi-Layer Strategies: Combine ablations across layers for enhanced effectiveness.
- Cross-Model Generalization: Test on other LLMs and concepts (e.g., sensitive data).
- Robust Evaluation: Use additional metrics (e.g., BLEU scores) and larger datasets.
- Disentanglement Techniques: Explore advanced SAE architectures to reduce feature entanglement.
Conclusion
This project underscores the power of Sparse Autoencoders for interpretable machine unlearning, with layer 12 ablation offering a balanced approach. The findings contribute to mechanistic interpretability, paving the way for ethical, adaptable LLMs. The main notebook can be found at this GitHub repository.
References
- Lieberum, T., et al. (2024). Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2.
- Ng, A. (2011). Sparse Autoencoder.
- Cao, Y., & Yang, J. (2019). Towards Making Systems Forget with Machine Unlearning.
- Eldan, R., & Russonovich, M. (2023). Who is Harry Potter? Exploring Fictional Character Representation in AI. Journal of AI Ethics, 10(2), 5-15.
Team Members and contribution
- Anirudh Belaguppa Manjunath - Ideation and Execution
- Sri Harsha P - Ideation