Style-based Global Appearance Flow For Virtual Try-On
Team Members: Jivesh Poddar, Dhruvi Gajjar, Neha CholeraIntroduction
Virtual mirrors are becoming the central focus of personalization and customer experience enhancement in retail. Thus the goal of our project is to improve Virtual Mirrors to enhance customer personalization and experience. It is basically a traditional mirror with a display behind the glass. Powered with computer vision cameras and AR, these mirrors can display a broad range of contextual information, which, in turn, helps buyers connect with the brand better. This ML-based engine provides its users with real-time fashion recommendations by observing their current outfits. Image-based virtual try-on targets draping a garment from an in-store rack over a digital representation of a person who is already dressed. The garment warping process, which involves aligning the target clothing with the relevant body components in the person's image, is an essential stage in the process of accomplishing this goal. The wrapping module is error-prone to challenging body positions or occlusions as well as substantial misalignments between the images of the person and the garments. In order to get over this limitation, our team focuses on an architecture based on a VTON(Virtual Try-On Network). A VTON model's job is to make a customer seem good in the clothes they sell in the store. One of the most important goals of a VTON model is to correctly connect the clothing being tried on in the store with the relevant body components in the image of the person being modeled.
Literature Survey
With the advancement in eCommerce, clothing has been a highly revenue-generating field. There numerous types of research & experiments have been proposed and tested for customer satisfaction with optimizing cost. About a decade ago, a virtual try-on was incorporated by the concept of parsing clothes, an idea similar to annotations in machine learning. Retrieving similar styles to parse clothing items. clothes parsing Yamaguchi, et al (2013) [2], clothing seen on the street to online products S. Liu, et al (2012) [3] fashion recommendation Y. Hu, et al (2015) [2], visual compatibility learning [7] and fashion trend prediction. A year later, making use of parsing technologies, a trend of recommendation shot up customer interest [3]. Then with AR technologies and integration with 3D visuals, virtual try-on became realistic with body shape and size.
GANs [6] showed promising advancement with their realistic generative results. Class labels, priorly done by image parsing helped in generating clothes with desired properties [7]. Labels also served as conditions in GANs. This idea was similar to the image-to-image translation using conditional GANs and it became the root of virtual-try-on. Image-to-image translation not only transformed the image into the desired output, i.e. fitting of clothes, sleeves length, cloth texture/material, etc but it also allowed training a CNN using a regression loss as an alternative to GANs for this task without adversarial training. These methods can produce photo-realistic images but have limited success when geometric changes occur [9]. GANs are computationally expensive, as high graphic computing is required to generated precise and realistic image.
There hasn't been much research done in computer vision to examine the virtual try-on problem. A conditional analogy GAN to exchange fashion items was recently presented by Jetchev and Bergmann [16]. However, they need product photos of both the target item and the original item on the individual during testing, which makes it impractical in real-world situations. Furthermore, without any human representing or explicitly considering deformations, it fails to provide photo-realistic virtual try-on results. Thus we focus on creating an accurate photo-realistic image straight from 2D photographs, which is more computationally economical, as opposed to relying on 3D measurements to accomplish perfect clothing simulation. Thus we focus on CP-VTON+ (Clothing shape and texture Preserving VTON (Virtual Try-On Network)) to overcome these issues, which significantly outperforms the state-of-the-art methods, both quantitatively and qualitatively.
Project Goal
Outfit Generation: The goal of this task is replace user's current outfit to target outfit and generate user's look.
About Data
We trained our model on the Zalando dataset. It contains a training set containing 14,221 image pairs and a t esting dataset of 2,032. Each pair means a person's image and the image of the garment on the person. Both person and garment images are of the resolution 256 x 192. We created a testing dataset, denoted by augmented VTON, to evaluate the model's robustness to the randomly positioned person image with larger misalignments with the garment images in the original dataset. It is split into approx 14.2k Training images and 2k testing images. We also included the Movenet dataset which helps our model to become shape and pose invariant. Later we added Alibaba Fashion Product Dataset from which we selected a few classes we had to work upon. We had to perform a lot of preprocessing and data augmentation steps. We made image resolution same for all the types of dataset for consistency. In the end, we were able to gather 30k images for training and 6k for validation and 4k images for testing.
Methods and Models
Resembled with the listed set of work, our concentration will be 2D images only. It will be challenging compared to contemporary work, which takes 3D input variables. From past implementations that focus on tweaking attributes(color and textures) of apparel [10] for interactive search we intend to improve with the VITON model. In the context of image-to-image translation for fashion applications, the main drawback of Yoo et al [5] was the transformation of a clothed person conditioned on a product image and backward. It ignored the condition of the model's pose. of the person's pose. Lassner et al. [11] proposed a model that lacked conditions/control on fashion items in the generated output. VTON first proposed the system setting and dataset of an in-shop cloth and a human target image. VTON also first used the two-stage architecture (a warping and a blending module) and CP-VTON (Clothing shape and texture Preserving VTON) [4] refined VTON for improving the clothing texture transfer, where the clothing area is blended with the warped cloth generated from the original cloth image, not reconstructing through a decoder network.
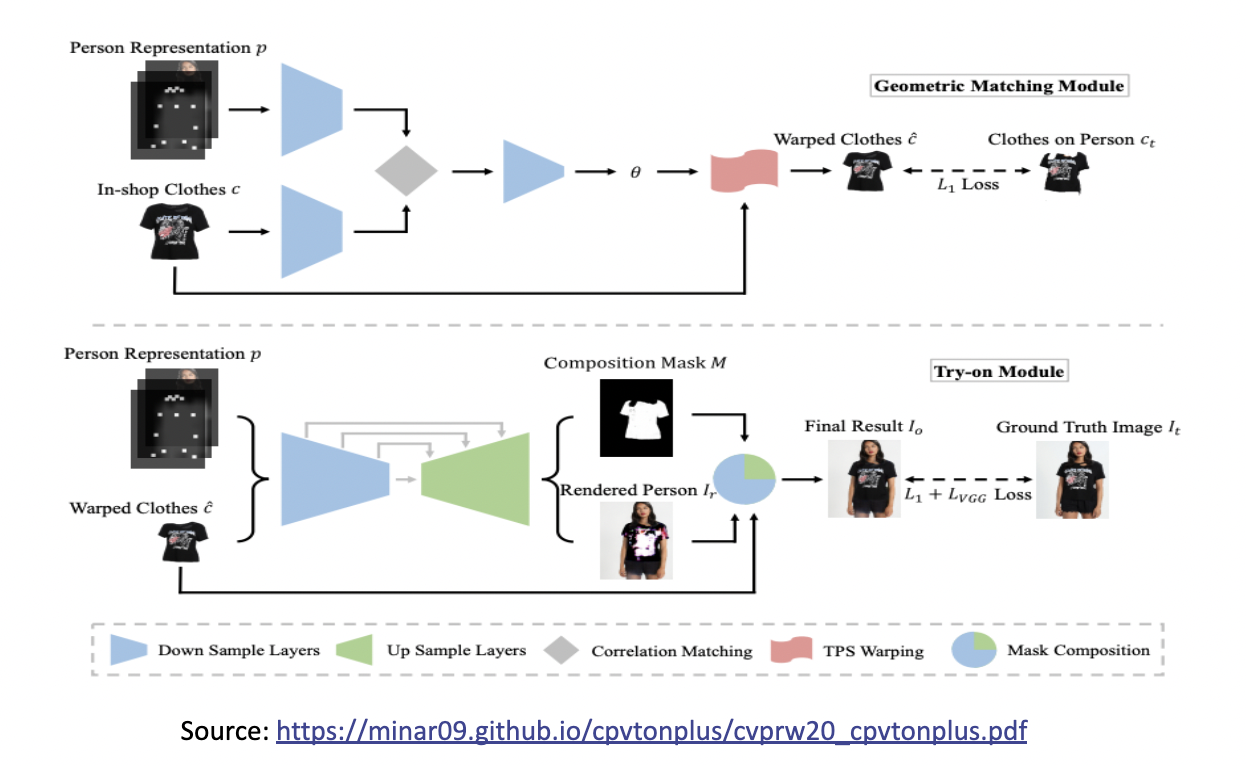
- Geometric Matching Module GMM: the in-shop clothes c and input image representation p are aligned via a learnable matching module
- Try-On Module: it generates a composition mask M and a rendered person Ir. The final result Io is composed of warped clothes c and the rendered person Ir with the composition mask M.

In Figure 1, First, the input image is transformed to its representation form p to feed to Geometric Machine Module by various labels (features) such as skin, hair, body, pose, background, etc.
Below is the figure of the CP-VTON module.
Failures of CPVTON

- Image 1&3: Looking at the Shoulder we see it drapes a normal two-shoulder t-shirt wrongly
- Image 2: Texture of IVY Park is not handled by try-module.
- Image 4: short sleeves to long sleeve matching are correct in wrapping module.
- Image 5: Misalignment of top's end (slant cut) and hand is incorrectly matched due to complex body pose
In CP-VTON we focused on improving GMM and Try-On-Module. The improvement of the GMM stage is in three aspects.
- It is crucial to obtain the complete target body silhouette area from the target human image. However, in the VTON dataset, the neck and bare chest area is wrongly labeled as background, and the body shape is often distorted by hair occlusion. Thus an extra new label 'skin' is added to the label set, and then the label of the corresponding area is restored from the wrong label, 'background', considering the original human image and joint locations. The skin-labeled area is now included in the silhouette in the human representation. To recover the hair occlusion over the body, first, the hair occlusion areas are identified as the intersection of the convex contour of the upper clothing and the hair-labeled area, and the intersections are re-labeled as upper cloth.
- The CP-VTON GMM network is built on CNN geometric matching and uses a pair of color images,
CP-VTON GMM inputs are binary mask information, silhouette, joint heatmap, and the colored try-on clothing.
Since the colored texture from try-on clothing does not help in the matching process,
GMM uses a clothing mask M_Ci instead of colored Ci.
In conclusion, the experiments conducted using the currently available techniques demonstrate that warped clothing frequently exhibits severe distortion. This can be seen very clearly when the garment type is a monogram, which means that it only has one color. In this case, the warping is not nearly as heavily distorted. However, when there are a variety of colors and textures present, the warping process blends the various textures, which results in an image that is distorted. Although we were unable to determine the exact cause, we are able to draw the conclusion that the estimation of the TPS parameters needs to be regularized so that it takes into account the restrictions placed on clothing textures. For the sake of easy visualization and comprehension, the regularization of grid warping is defined on the grid deformation rather than directly on the TPS parameters. This is done in order to avoid having a warping that is too dissimilar from that of the previous and subsequent grid gaps in the equation.
The new improved model looks like below:
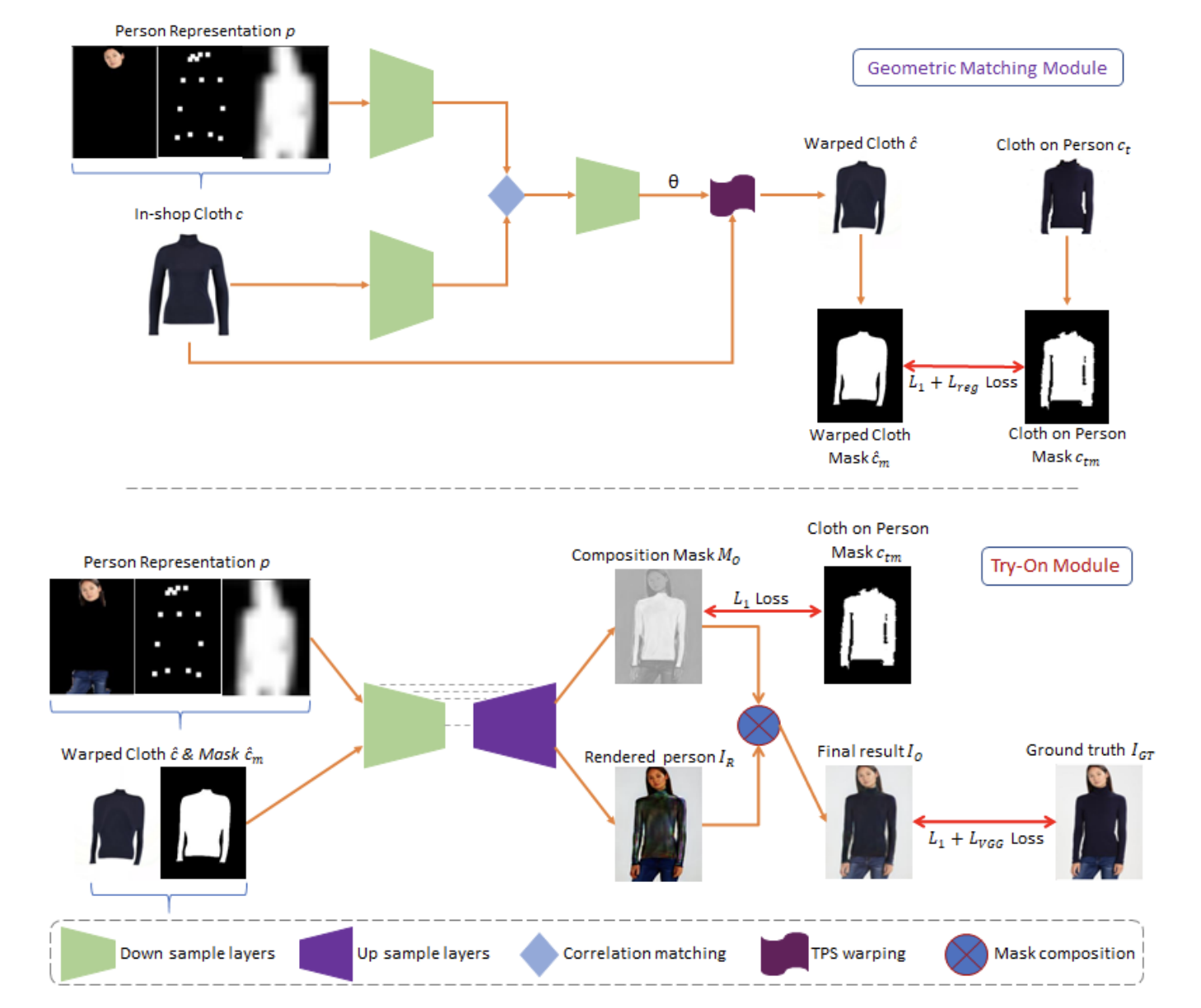
The red Arrows show improvement areas with combined losses in the GMM module & Try on the module. Loss Functions
The Loss function of CP-VTON is improvised as follows. We have used λ1 for regularisation with the previous loss L1. Previous loss L1 was basically SSIM (Similarity index & LPIPS on Wrapped cloth generation).
We also used λreg as a parameter to scale the weightage of newly added Regularised loss Lreg. We have also used the reference of regularisation to GMM loss to combining with the original loss. Thus, these are new loss equations.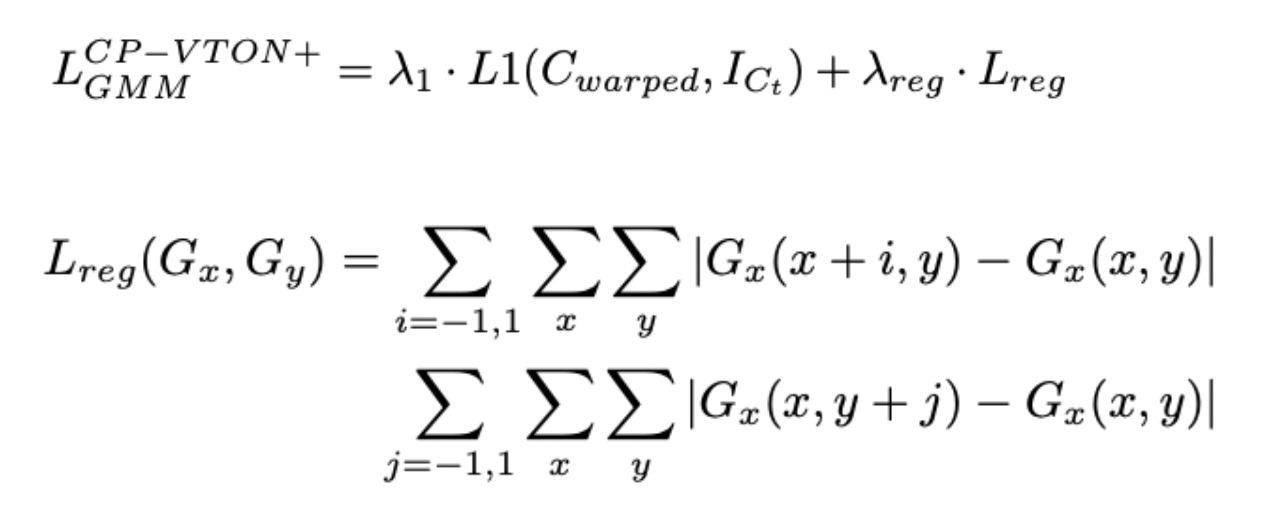
- To solve our third aspect, we extended the existing CP-VTON implementation as described above. We used automatic refinement for segmentation. i.e. improved loss function to adjust refinement automatically. For training, we started with a similar setting, keeping lambda_1 = 1 and lambda_reg = 0.5. This allowed us to compare the results of CP-VTON with newly added regularisations. We used all the dataset pairs dataset for all experiments. We kept the learning rate first fixed at 0.0001 for 100K steps and then linearly decay to zero for the remaining steps.
Results and Findings
We have compared the CP-VTON+ model with the already implemented CP-VTON model on the following metrics followed by image output.
- IoU: Intersection over Union A number that quantifies the degree of overlap between two boxes. In the case of object detection and segmentation, IoU evaluates the overlap of the Ground Truth and Prediction region. Any score above 0.7-0.8 is a good score a suggesting 70-80% intersection.
- SSIM: Structural Similarity Index Measure The Structural Similarity Index Measure metric compares two images on three main features. Structure, Luminance, and Contrast. Since one of the major failures in VTON is losing texture, and miscalculating skin color with cloth color or background. SSIM metric compares the model-generated output with actual output to give a score on the listed three features. results below show how improving SSIM has resulted in great texture perseverance. We have used standard formula for calculating SSIM . Similar to IoU any score above 0.7-0.8 is a good score suggesting a 70-80% similarity index.
- LPIPS: Learned Perceptual Image Patch Similarity When there is supervised machine learning, i.e. we have the real output we use perceptual similarity to calculate how near the output image's active patch is to the original image's active patch. Thus LPIPS evaluates the distance between image patches. Higher means further/more different. Lower means more similar. We have used an inbuilt python function to calculate this metric. This is a difference score so, the lesser the score the better! below 10% difference is a good score.
- IS: Inception Score Whenever there is unsupervised machine learning, i.e. output doesn't have expected try-on output for comparison we use the Inception Score with mean and standard deviation. IS a technique used to assess the quality of image output by try-on Module (generative adversarial network). The score is calculated based on the output of a separate, pretrained Inceptionv3 image classification model applied to a sample of images generated by the generative model. We have used the PyTorch IS function to calculate this. ref Wikipedia . The inception Score is relative. Thus higher the score the better.
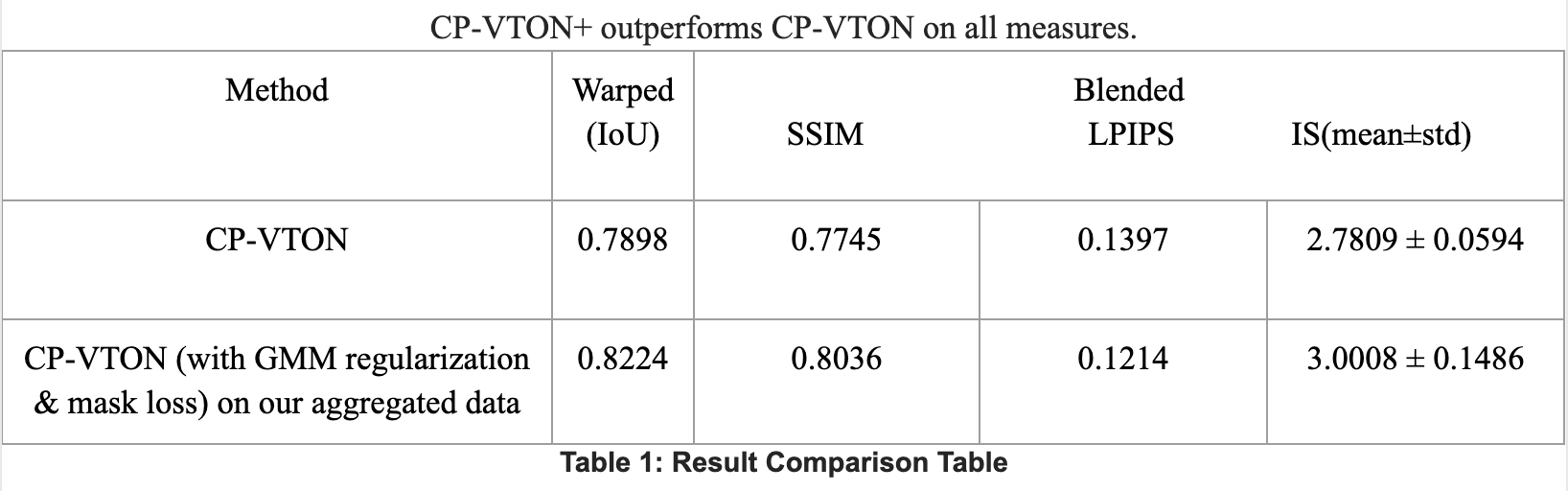
- IoU: The wrapping module is measured by IoU (Intersection over Union) which is now improved from 0.78 to 0.82.
- SSIM & LPIPS: Due to extra labels, the Try-on results are measured by SSIM Structural similarity index measure and Learned Perceptual Image Patch Similarity (LPIPS) metrics. For the same clothing retry-on cases when we have ground truths for the warping stage and the blending stage, we can see SSIM is increased to 0.8036. The original target human image is used as the reference image for SSIM and LPIPS (a lower score means better), and the parsed segmentation area for the current upper clothing is used as the IoU reference.
- IS: For different clothing try-on (where no ground truth is available), we used the Inception Score (IS).

Here, we tested the CPVTON+ model with 3 different kinds of input styles and you can see the results. The left one is CP-VTON and the right one is the improved CP-VTON+ model. For the first image, we can see the referenced image is wearing a one-shoulder striped top and the target cloth is a normal two-shoulder T-shirt. We can see that the CPVTON+ model has generated the output more accurately than the CP-VTON. Similarly for cold shoulder T-shirt. CPVTON has misaligned again whereas improved CPVTON+ has tried to predict hand line & thus try-on sleeve of target variable almost accurate The last referenced image has been taken from Alibaba's Fashion dataset with a background and we have removed the background produced desired output.
Our Addings
We compared the CPVITON and CPVITON+ architecture on various parameters.
The neck and bare chest area is wrongly labeled as background, and the body shape is often distorted by hair occlusion. Thus a new label 'skin' is added to the label set, and then the label of the corresponding area is restored from the wrong label, 'background', considering the original human image and joint locations. The skin-labeled area is now included in the human representation.
The experiments with CPVITON reveals that warped clothing is often severely distorted. When the clothing type is in monogram, i.e. having just one color, the warping is not that heavily distorted. However, when there are multiple colors and textures, the warping blends the different textures, resulting in a distorted image. Which estimates the need of a regularization, taking into account the restriction of clothing textures.
There is significant improvement in evaluation metrics and we see output generated are more realistic. They are shape & pose invariant as well as preserving texture, Apart from the dataset given in the research paper we referred to, we extended our approach to test this model on multiple datasets. And results are satisfactory.
Future Scope
Outfit Recommendation: This goal is notifying the user based on these input details such as a person, occasion, color size, etc this dress would look great. Here, a set of objects is recommended to the user at once, by maximizing a utility function that measures the suitability of guiding a fashion outfit to a specific user. We propose OutfitGAN, which generates/recommends a newly discovered fashion item that matches well with the items already in an outfit. We use relational networks to capture item compatibility in fashion outfits. We re-use a pretrained Compatibility Scoring Network (CSN) as a sub-module of OutfitGAN, which has to learn compatibility among fashion items via relational networks.
Team Members and Contribution
Each member of our group has significantly contributed to the project using their expertise. Dhruvi and Neha took ownership of research, EDA and Data analysis. Jivesh took ownership of the modeling part. But at each step we kept each other updated and took decisions collectively.
References
[1] A Review of Modern Fashion Recommender Systems
[2] Style-Based Global Appearance Flow for Virtual Try-On
[3] A Curated List of Awesome Virtual Try-on (VTON) Research
[4] Multi-Garment: Learning to Dress 3D People from Images
Citatations
[1] S. Yang, T. Ambert, Z. Pan, K. Wang, L. Yu, T. Berg, and M. C. Lin. Detailed garment recovery from a single-view image. In ICCV, 2017
[2] Yamaguchi, M. Hadi Kiapour, and T. L. Berg. Paper doll parsing: Retrieving similar styles to parse clothing items. In ICCV, 2013.
[3] S. Liu, Z. Song, G. Liu, C. Xu, H. Lu, and S. Yan. Street-toshop: Cross-scenario clothing retrieval via parts alignment and auxiliary set. In CVPR, 2012.
[4] Y. Hu, X. Yi, and L. S. Davis. Collaborative fashion recommendation a functional tensor factorization approach. In ACM Multimedia, 2015.
[5] D. Yoo, N. Kim, S. Park, A. S. Paek, and I. S. Kweon. In ECCV, 2016
[6] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio Generative adversarial nets. In NIPS, 2014
[6] A. Odena, C. Olah, and J. Shlens. Conditional image synthesis with auxiliary classifier gans. In ICML, 2017
[7] X. Han, Z. Wu, Y.-G. Jiang, and L. S. Davis. Learning fashion compatibility with bidirectional lstms. In ACM Multimedia, 2017.
[8] A. Kovashka, D. Parikh, and K. Grauman. Whittlesearch: Image search with relative attribute feedback. In CVPR, 2012.
[10] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In ICCV, 2017
[11] C. Lassner, G. Pons-Moll, and P. V. Gehler. A generative model of people in clothing. In ICCV, 2017
[12] C. S. Zhu, S. Fidler, R. Urtasun, D. Lin, and C. L. Chen. A generative. Be your own prada: Fashion synthesis with structural coherence. In ICCV, 2017
[13] P. Guan, L. Reiss, D. A. Hirshberg, A. Weiss, and M. J. Black Drape: Dressing any person. ACM TOG, 2012
[14] M. Sekine, K. Sugita, F. Perbet, B. Stenger, and M. Nishiyama. Virtual fitting by single-shot body shape estimation. In 3D Body Scanning Technologies, 2014
[15] S. Yang, T. Ambert, Z. Pan, K. Wang, L. Yu, T. Berg, and M. C. Lin. Detailed garment recovery from a single-view image. In ICCV, 2017
[16] N. Jetchev and U. Bergmann. The conditional analogy gan: Swapping fashion articles on people images. In ICCVW, 2017.