What are vision transformers, how has transformers become better at solving depth estimation with single image?
Is AI able to solve problem which humans can't naturally?
Dataset
There are two datasets that we tried working. Kitti dataset beting too large we thought of just running the testset once we built the model using other datasets. For training validation dataset of the below models were used for now as the actual training datasets are as large as 84gb.
DIODE
DIODE (Dense Indoor and Outdoor DEpth) is a dataset that contains diverse high-resolution color images with accurate, dense, far-range depth measurements. It is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. The dataset contains an RGB image and a depth image, where the closer objects have blue color and as it goes back the farthest object has red color.
 |
NYU-Depth V2
We used the labelled dataset of NYU-2 which is close to 2.8GB. It is comprised of pairs of RGB and Depth frames that have been synchronized and annotated with dense labels for every image.
 |
Model Architecture
As part of our initial analysis of the project we implemented a UNet CNN with a ResNet34 encoder which uses weights pre-trained on imagenet. U-Net has two parts an encoder and a decoder. The encoder decoder set up allows us to encode the RGB image and get back the same image but in a different form(depth based colored). U-Net has the ability for pixel-level localization and distinguishes unique patterns. Each block of the decoder is connected to the corresponding block of the encoder using Skip connections. This helps it to have more latent spaces than its traditional counterpart and that said, it uses the information right from the input space and all of its intermediate representations to map the sample onto some well-defined latent space and then computing the output from it. These skip connections are experimentally validated in many pieces of research to solve the degradation problem.
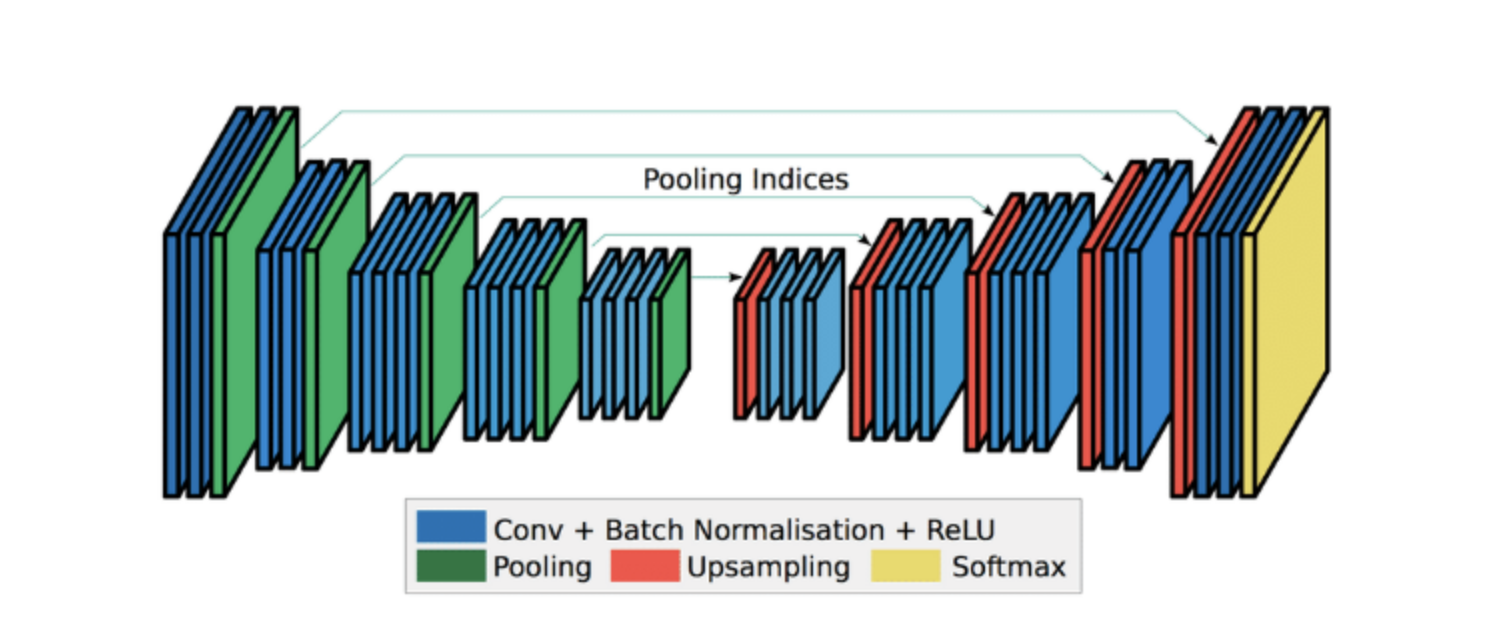 |
Implementation Details
For our dataset, we used NYU-V2 [2] validation dataset and, split the dataset into train and test. The folder format of the dataset can be seen here [2]. The training set if further split into 70% train and 30% validation datasets. As part of data preprocessing we perform random horizontal flips of the image and normalize the images. We used an image size of 128*128 with 3 RGB channels as input. For hyperparameters, we used 16 batch size, 15 epochs, 0.0001 learning rate.
Findings
In the beginning we started to understand the Kitti datasets, because the dataset is built using an autonomous driving platform. But due to the dataset being large we decided to train our model on DIODE dataset. To begin with we ran a trial run on a pre-trained vision transformer to understand how well the depth estimation it was able to do with respect to the ground truth. Thereafter as part of our first steps, we implemented a pipeline to perform the following
- Split the dataset into validation and train.
- Peform preprocessing on the images, normalize and create augmented data.
- Train the model for given number of epochs with loss function as the absolute differennce between the true predicction and the ground truth. The model starts with the pre-trained weights of imagenet.

|
We can see that for a 15 epoch, using pretrained weights the model does an okay job at least for understanding what is near and what is far. But the model does do a good job at proper segmentation. When there are too many objects in the image the model does not do a good job. We feel self attention and increasing the number of epochs might help improve this. With self-attention the model might undertand what pixels might be related in terms ob the object and the orientation in an image.
We see that the training for a 128*128 vision transformer would require a high computational power, so we are putting a hold on the project for now and trying to get a indepth understanding of Transformers and BERT, and how self-attention has become a game changer. We are planning to utilize BERT to build a Question Answering model trained to answer questions from COVID related research articles.(Click here for details)
References
[1] Vision Transformers for Dense Prediction.
[2] https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
[3] https://gitlab.com/AshwinUnnikrishnan/monocular-depth
[4] https://medium.com/mlearning-ai/monocular-depth-estimation-using-u-net-6f149fc34077
[5] https://huggingface.co/Intel/dpt-large
Team Members
Click here for our problem statement and plan for COVID-19 QA system using BERT